# Illustrate prompt engineering principles with constructed examples
# (No live API call — we show the prompt structure and a simulated response)
library(tidyverse)
# ── Example 1: Vague vs. specific prompts ─────────────────────────────────────
vague_prompt <- "Summarise this report."
specific_prompt <- "
You are a financial analyst at a Lagos Business School research unit.
Summarise the following quarterly earnings report in exactly 3 bullet points.
Each bullet should be 1 sentence. Focus on: revenue, costs, and outlook.
Audience: non-technical board members.
Report:
'Zenith Bank Plc reported Q3 2025 gross earnings of ₦487.2 billion, up 34% year-on-year,
driven by a 41% increase in interest income as the MPR held at 26.75%. Operating costs
rose 28% to ₦162 billion, largely due to technology investment and staff costs. Management
expects Q4 earnings to remain strong, citing robust loan book growth and FX gains,
though they flagged rising NPL pressure in the SME segment as a key risk to monitor.'
"
# ── Example 2: Few-shot classification ────────────────────────────────────────
few_shot_prompt <- "
Classify each customer complaint as: Billing / Technical / Service Quality / Other.
Examples:
Complaint: 'I was charged twice for the same month.' → Billing
Complaint: 'My internet keeps dropping every evening.' → Technical
Complaint: 'The agent was rude and unhelpful.' → Service Quality
Complaint: 'I want to change my package.' → Other
Now classify:
Complaint: 'My data bundle expired before I used it.' → ?
"
# ── Example 3: Chain-of-thought for reasoning ─────────────────────────────────
cot_prompt <- "
You are a supply chain analyst. Think step by step before answering.
A warehouse holds 5,000 units. Weekly demand is 800 units.
Lead time from supplier is 3 weeks. The reorder point (ROP) is:
ROP = Average Weekly Demand × Lead Time Weeks.
Safety stock adds 1 week of demand.
What is the ROP? Show your working.
"
cat("=== Prompt Structure Comparison ===\n\n")
#> === Prompt Structure Comparison ===
cat("VAGUE (avoid):\n", vague_prompt, "\n\n")
#> VAGUE (avoid):
#> Summarise this report.
cat("SPECIFIC (prefer):\n", specific_prompt, "\n\n")
#> SPECIFIC (prefer):
#>
#> You are a financial analyst at a Lagos Business School research unit.
#> Summarise the following quarterly earnings report in exactly 3 bullet points.
#> Each bullet should be 1 sentence. Focus on: revenue, costs, and outlook.
#> Audience: non-technical board members.
#>
#> Report:
#> 'Zenith Bank Plc reported Q3 2025 gross earnings of ₦487.2 billion, up 34% year-on-year,
#> driven by a 41% increase in interest income as the MPR held at 26.75%. Operating costs
#> rose 28% to ₦162 billion, largely due to technology investment and staff costs. Management
#> expects Q4 earnings to remain strong, citing robust loan book growth and FX gains,
#> though they flagged rising NPL pressure in the SME segment as a key risk to monitor.'
#>
cat("FEW-SHOT example:\n", few_shot_prompt, "\n")
#> FEW-SHOT example:
#>
#> Classify each customer complaint as: Billing / Technical / Service Quality / Other.
#>
#> Examples:
#> Complaint: 'I was charged twice for the same month.' → Billing
#> Complaint: 'My internet keeps dropping every evening.' → Technical
#> Complaint: 'The agent was rude and unhelpful.' → Service Quality
#> Complaint: 'I want to change my package.' → Other
#>
#> Now classify:
#> Complaint: 'My data bundle expired before I used it.' → ?
#> 62 Generative AI and Large Language Models in Business
62.1 Introduction: A Different Kind of AI
Every previous chapter in this book has dealt with discriminative AI — models that predict a label, a number, or a cluster assignment from input features. A fraud detection model asks: given this transaction’s features, is it fraudulent? A churn model asks: given this customer’s behaviour, will they leave?
Generative AI is different. Instead of classifying or predicting, it generates — it produces new text, images, code, or data. A large language model (LLM) does not look up a stored answer; it constructs a response word-by-word, based on patterns learned from billions of examples of human writing.
This shift has profound business implications. Tasks that previously required expensive human expertise — drafting reports, summarising documents, writing code, classifying customer feedback, translating languages — can now be automated or augmented at scale.
By 2026, every serious analytics function will incorporate LLMs in some part of its workflow. This chapter gives you the foundations to use them intelligently.
62.2 How Large Language Models Work
62.2.1 The Transformer Architecture
Modern LLMs are built on the Transformer architecture, introduced in the landmark 2017 paper “Attention Is All You Need”. The key innovation is self-attention: the ability to relate every word in a sequence to every other word, regardless of distance.
At training time, the model is given billions of text examples and learns to predict the next word (technically the next token) given all preceding tokens. This simple objective, applied at enormous scale, gives rise to remarkably general capabilities.
62.2.2 Scale and Emergence
LLMs become qualitatively more capable as scale increases — model parameters, training data, and compute are all critical. Behaviours such as multi-step reasoning, analogy-making, and code generation emerge above certain scale thresholds and cannot be predicted by extrapolating from small models.
The major families in 2026:
| Family | Organisation | Typical Use |
|---|---|---|
| GPT-4o / GPT-4.5 | OpenAI | General purpose, API access |
| Claude 3.x | Anthropic | Long-context, safety-focused |
| Gemini 1.5 / 2.0 | Multimodal, 1M token context | |
| Llama 3.x | Meta | Open-source, deployable locally |
| Mistral / Mixtral | Mistral AI | Efficient, open-source |
For African business contexts, access is typically through cloud APIs (OpenAI, Anthropic, Google) or locally-deployed open-source models.
62.3 Prompt Engineering
The single highest-leverage skill for using LLMs in business is prompt engineering: structuring your inputs to reliably elicit useful outputs.
62.3.1 Core Principles
1. Be specific and explicit. Vague prompts produce vague responses. State your task, desired format, length, and audience.
2. Provide context. LLMs do not know your organisation, your data, or your specific problem. Give them what they need.
3. Use examples (few-shot prompting). Showing the model 2–3 input-output pairs dramatically improves consistency.
4. Assign a role. “You are a senior credit analyst at a Nigerian commercial bank” primes the model to adopt relevant domain knowledge.
5. Chain of thought. For complex reasoning, ask the model to “think step by step” before giving a final answer.
Show code
# Show prompt structures as strings — no live API key required
few_shot_prompt = """
Classify each customer complaint as: Billing / Technical / Service Quality / Other.
Examples:
Complaint: 'I was charged twice for the same month.' → Billing
Complaint: 'My internet keeps dropping every evening.' → Technical
Complaint: 'The agent was rude and unhelpful.' → Service Quality
Complaint: 'I want to change my package.' → Other
Now classify:
Complaint: 'My data bundle expired before I used it.' → ?
Complaint: 'The network coverage is poor in Surulere.' → ?
"""
system_role = (
"You are a senior credit risk analyst at a Nigerian commercial bank. "
"Your responses should reflect Basel III terminology and IFRS 9 standards."
)
cot_template = """
Problem: {problem}
Think through this step by step:
1. Identify the key variables.
2. Apply the relevant formula or framework.
3. State your final answer with a one-sentence business interpretation.
"""
print("=== Prompt Engineering Examples ===\n")
#> === Prompt Engineering Examples ===
print("Few-shot classification prompt:")
#> Few-shot classification prompt:
print(few_shot_prompt)
#>
#> Classify each customer complaint as: Billing / Technical / Service Quality / Other.
#>
#> Examples:
#> Complaint: 'I was charged twice for the same month.' → Billing
#> Complaint: 'My internet keeps dropping every evening.' → Technical
#> Complaint: 'The agent was rude and unhelpful.' → Service Quality
#> Complaint: 'I want to change my package.' → Other
#>
#> Now classify:
#> Complaint: 'My data bundle expired before I used it.' → ?
#> Complaint: 'The network coverage is poor in Surulere.' → ?
print("\nSystem role primer:")
#>
#> System role primer:
print(system_role)
#> You are a senior credit risk analyst at a Nigerian commercial bank. Your responses should reflect Basel III terminology and IFRS 9 standards.
print("\nChain-of-thought template:")
#>
#> Chain-of-thought template:
print(cot_template.format(problem="Calculate the DSCR if EBITDA = ₦450m and annual debt service = ₦120m."))
#>
#> Problem: Calculate the DSCR if EBITDA = ₦450m and annual debt service = ₦120m.
#>
#> Think through this step by step:
#> 1. Identify the key variables.
#> 2. Apply the relevant formula or framework.
#> 3. State your final answer with a one-sentence business interpretation.62.4 Using LLM APIs in Practice
62.4.1 Setting Up API Access
In practice, you call an LLM through an HTTP API. Below we show the structure of an OpenAI-compatible API call. The actual response content depends on your API key and the model you access.
Important
Never hard-code API keys in shared scripts or notebooks. Store them as environment variables or in a secrets manager. In R, use Sys.getenv("OPENAI_API_KEY"); in Python, use os.environ["OPENAI_API_KEY"].
Show code
# Demonstrate the API call structure without a live key
# In production, replace the simulated response with an actual API call
library(tidyverse)
# ── API call template ──────────────────────────────────────────────────────────
make_llm_request <- function(prompt, system = "You are a helpful business analytics assistant.",
model = "gpt-4o", temperature = 0.3) {
# In production, use httr2::request() / httr2::req_perform()
# Here we show the request structure
list(
model = model,
temperature = temperature,
messages = list(
list(role = "system", content = system),
list(role = "user", content = prompt)
)
)
}
# Build an example request
req <- make_llm_request(
prompt = "List three KPIs a Nigerian retail bank should track weekly. Format as a numbered list.",
system = "You are a senior banking analyst with expertise in Nigerian financial markets."
)
cat("=== API Request Structure ===\n")
#> === API Request Structure ===
cat("Model: ", req$model, "\n")
#> Model: gpt-4o
cat("Temperature: ", req$temperature, "\n")
#> Temperature: 0.3
cat("System msg: ", req$messages[[1]]$content, "\n")
#> System msg: You are a senior banking analyst with expertise in Nigerian financial markets.
cat("User prompt: ", req$messages[[2]]$content, "\n")
#> User prompt: List three KPIs a Nigerian retail bank should track weekly. Format as a numbered list.
# ── Simulated response (what an LLM would return) ─────────────────────────────
simulated_response <- "
1. **Non-Performing Loan (NPL) Ratio** — Measures the percentage of loans where
borrowers are 90+ days past due. Target: below 5% (CBN threshold).
2. **Net Interest Margin (NIM)** — Net interest income as a percentage of
earning assets. Tracks the profitability of the lending book.
3. **Liquidity Coverage Ratio (LCR)** — High-quality liquid assets divided by
30-day net cash outflows. Regulatory minimum: 100%.
"
cat("\n=== Simulated LLM Response ===\n")
#>
#> === Simulated LLM Response ===
cat(simulated_response, "\n")
#>
#> 1. **Non-Performing Loan (NPL) Ratio** — Measures the percentage of loans where
#> borrowers are 90+ days past due. Target: below 5% (CBN threshold).
#>
#> 2. **Net Interest Margin (NIM)** — Net interest income as a percentage of
#> earning assets. Tracks the profitability of the lending book.
#>
#> 3. **Liquidity Coverage Ratio (LCR)** — High-quality liquid assets divided by
#> 30-day net cash outflows. Regulatory minimum: 100%.
#> Show code
import json
# Show API request structure without a live call
def build_request(prompt, system="You are a helpful business analytics assistant.",
model="gpt-4o", temperature=0.3):
return {
"model": model,
"temperature": temperature,
"messages": [
{"role": "system", "content": system},
{"role": "user", "content": prompt}
]
}
req = build_request(
prompt="List three KPIs a Nigerian retail bank should track weekly. Numbered list.",
system="You are a senior banking analyst with expertise in Nigerian financial markets."
)
print("=== API Request Structure ===")
#> === API Request Structure ===
print(json.dumps(req, indent=2))
#> {
#> "model": "gpt-4o",
#> "temperature": 0.3,
#> "messages": [
#> {
#> "role": "system",
#> "content": "You are a senior banking analyst with expertise in Nigerian financial markets."
#> },
#> {
#> "role": "user",
#> "content": "List three KPIs a Nigerian retail bank should track weekly. Numbered list."
#> }
#> ]
#> }
# Simulated response
simulated = """
1. NPL Ratio — Non-performing loans / total loans. CBN threshold: < 5%.
2. Net Interest Margin — Interest income net of funding costs / earning assets.
3. Liquidity Coverage Ratio — HQLA / 30-day net outflows. Minimum: 100%.
"""
print("\n=== Simulated LLM Response ===")
#>
#> === Simulated LLM Response ===
print(simulated)
#>
#> 1. NPL Ratio — Non-performing loans / total loans. CBN threshold: < 5%.
#> 2. Net Interest Margin — Interest income net of funding costs / earning assets.
#> 3. Liquidity Coverage Ratio — HQLA / 30-day net outflows. Minimum: 100%.62.5 Text Classification and Extraction at Scale
One of the most practical LLM use cases is processing large volumes of unstructured text — customer feedback, contract clauses, incident reports — to extract structured labels or entities. LLMs outperform classical NLP pipelines on these tasks when:
- Labels are nuanced (beyond simple sentiment)
- Training data is scarce
- The task definition evolves over time
Show code
library(tidyverse)
# Simulate a corpus of Nigerian bank customer complaints
set.seed(4827)
complaints <- tibble(
id = 1:20,
text = c(
"I was charged ₦5,000 twice for the same transfer",
"My ATM card was swallowed at the Lekki branch",
"The mobile app keeps crashing when I try to send money",
"I have been waiting 3 weeks for my statement — still not received",
"Excellent service at Ikeja branch, very professional staff",
"My account was debited without authorisation",
"The customer service line rings for 30 minutes with no answer",
"Why is my credit limit lower than what was promised?",
"Transfer to GTB failed and the money left my account",
"Interest on my loan was calculated incorrectly",
"The new app is great, much faster than before",
"I lost my card but the replacement is taking too long",
"My salary was not reflected even though my employer says they paid",
"Hidden charges on my current account — nobody told me about these",
"Branch closes at 4pm sharp, difficult for working people",
"Online banking portal shows wrong balance",
"Staff at Victoria Island branch were very helpful",
"I cannot view my transactions from more than 3 months ago",
"BVN linkage still pending after 6 weeks",
"Great experience opening my account online, took only 10 minutes"
)
)
# In production: send each complaint to an LLM API and parse the JSON response
# Here: simulate the output a well-prompted LLM would return
llm_classifications <- tibble(
id = 1:20,
category = c("Billing", "Branch Operations", "Digital Channel", "Account Services",
"Positive", "Fraud/Security", "Customer Service", "Credit",
"Digital Channel", "Billing", "Positive", "Card Services",
"Payments", "Billing", "Branch Operations", "Digital Channel",
"Positive", "Digital Channel", "Account Services", "Positive"),
urgency = c("High", "High", "Medium", "Low", "Low", "Critical", "Medium",
"Medium", "High", "Medium", "Low", "Low", "High", "Medium",
"Low", "Medium", "Low", "Low", "Low", "Low"),
sentiment = c("Negative", "Negative", "Negative", "Negative", "Positive",
"Negative", "Negative", "Negative", "Negative", "Negative",
"Positive", "Negative", "Negative", "Negative", "Negative",
"Negative", "Positive", "Negative", "Negative", "Positive")
)
results <- complaints |> left_join(llm_classifications, by = "id")
cat("=== LLM-Classified Customer Complaints (Sample) ===\n\n")
#> === LLM-Classified Customer Complaints (Sample) ===
print(results |> select(id, category, urgency, sentiment, text) |> head(10))
#> # A tibble: 10 × 5
#> id category urgency sentiment text
#> <int> <chr> <chr> <chr> <chr>
#> 1 1 Billing High Negative I was charged ₦5,000 twice for th…
#> 2 2 Branch Operations High Negative My ATM card was swallowed at the …
#> 3 3 Digital Channel Medium Negative The mobile app keeps crashing whe…
#> 4 4 Account Services Low Negative I have been waiting 3 weeks for m…
#> 5 5 Positive Low Positive Excellent service at Ikeja branch…
#> 6 6 Fraud/Security Critical Negative My account was debited without au…
#> 7 7 Customer Service Medium Negative The customer service line rings f…
#> 8 8 Credit Medium Negative Why is my credit limit lower than…
#> 9 9 Digital Channel High Negative Transfer to GTB failed and the mo…
#> 10 10 Billing Medium Negative Interest on my loan was calculate…
# Summary statistics
cat("\n=== Category Distribution ===\n")
#>
#> === Category Distribution ===
print(results |> count(category, sort = TRUE))
#> # A tibble: 10 × 2
#> category n
#> <chr> <int>
#> 1 Digital Channel 4
#> 2 Positive 4
#> 3 Billing 3
#> 4 Account Services 2
#> 5 Branch Operations 2
#> 6 Card Services 1
#> 7 Credit 1
#> 8 Customer Service 1
#> 9 Fraud/Security 1
#> 10 Payments 1
cat("\n=== Urgent Issues Requiring Immediate Action ===\n")
#>
#> === Urgent Issues Requiring Immediate Action ===
print(results |> filter(urgency == "Critical" | (urgency == "High" & sentiment == "Negative")) |>
select(id, category, text))
#> # A tibble: 5 × 3
#> id category text
#> <int> <chr> <chr>
#> 1 1 Billing I was charged ₦5,000 twice for the same transfer
#> 2 2 Branch Operations My ATM card was swallowed at the Lekki branch
#> 3 6 Fraud/Security My account was debited without authorisation
#> 4 9 Digital Channel Transfer to GTB failed and the money left my account
#> 5 13 Payments My salary was not reflected even though my employer s…Show code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(4827)
complaints = pd.DataFrame({
'id': range(1, 21),
'text': [
"I was charged twice for the same transfer",
"My ATM card was swallowed at the Lekki branch",
"The mobile app keeps crashing when I try to send money",
"I have been waiting 3 weeks for my statement",
"Excellent service at Ikeja branch, very professional",
"My account was debited without authorisation",
"The customer service line rings for 30 minutes with no answer",
"Why is my credit limit lower than what was promised?",
"Transfer to GTB failed and the money left my account",
"Interest on my loan was calculated incorrectly",
"The new app is great, much faster than before",
"I lost my card but the replacement is taking too long",
"My salary was not reflected",
"Hidden charges on my current account",
"Branch closes at 4pm, difficult for working people",
"Online banking portal shows wrong balance",
"Staff at Victoria Island branch were very helpful",
"I cannot view transactions from more than 3 months ago",
"BVN linkage still pending after 6 weeks",
"Great experience opening my account online"
],
'category': [
"Billing", "Branch Operations", "Digital Channel", "Account Services",
"Positive", "Fraud/Security", "Customer Service", "Credit",
"Digital Channel", "Billing", "Positive", "Card Services",
"Payments", "Billing", "Branch Operations", "Digital Channel",
"Positive", "Digital Channel", "Account Services", "Positive"
],
'urgency': [
"High", "High", "Medium", "Low", "Low", "Critical", "Medium",
"Medium", "High", "Medium", "Low", "Low", "High", "Medium",
"Low", "Medium", "Low", "Low", "Low", "Low"
],
'sentiment': [
"Negative"] * 4 + ["Positive"] + ["Negative"] * 5 + ["Positive"] +
["Negative"] * 4 + ["Positive"] + ["Negative"] * 3 + ["Positive"]
})
print("=== LLM-Classified Complaints (first 10) ===")
#> === LLM-Classified Complaints (first 10) ===
print(complaints[['id', 'category', 'urgency', 'text']].head(10).to_string(index=False))
#> id category urgency text
#> 1 Billing High I was charged twice for the same transfer
#> 2 Branch Operations High My ATM card was swallowed at the Lekki branch
#> 3 Digital Channel Medium The mobile app keeps crashing when I try to send money
#> 4 Account Services Low I have been waiting 3 weeks for my statement
#> 5 Positive Low Excellent service at Ikeja branch, very professional
#> 6 Fraud/Security Critical My account was debited without authorisation
#> 7 Customer Service Medium The customer service line rings for 30 minutes with no answer
#> 8 Credit Medium Why is my credit limit lower than what was promised?
#> 9 Digital Channel High Transfer to GTB failed and the money left my account
#> 10 Billing Medium Interest on my loan was calculated incorrectly
print("\n=== Category Distribution ===")
#>
#> === Category Distribution ===
print(complaints['category'].value_counts().to_string())
#> category
#> Positive 4
#> Digital Channel 4
#> Billing 3
#> Branch Operations 2
#> Account Services 2
#> Fraud/Security 1
#> Customer Service 1
#> Credit 1
#> Card Services 1
#> Payments 1
# Visualise
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
cat_counts = complaints['category'].value_counts()
axes[0].barh(cat_counts.index, cat_counts.values, color='steelblue')
axes[0].set_xlabel('Count')
axes[0].set_title('Complaints by Category')
axes[0].grid(axis='x', alpha=0.3)
urgency_sent = complaints.groupby(['urgency', 'sentiment']).size().unstack(fill_value=0)
urgency_order = ['Critical', 'High', 'Medium', 'Low']
urgency_sent = urgency_sent.reindex([u for u in urgency_order if u in urgency_sent.index])
urgency_sent.plot(kind='bar', ax=axes[1], color=['steelblue', 'coral'])
axes[1].set_xlabel('Urgency')
axes[1].set_ylabel('Count')
axes[1].set_title('Urgency vs Sentiment')
axes[1].tick_params(axis='x', rotation=0)
axes[1].legend(title='Sentiment')
axes[1].grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.savefig("ch57_complaint_classification.png", dpi=150, bbox_inches='tight')
plt.show()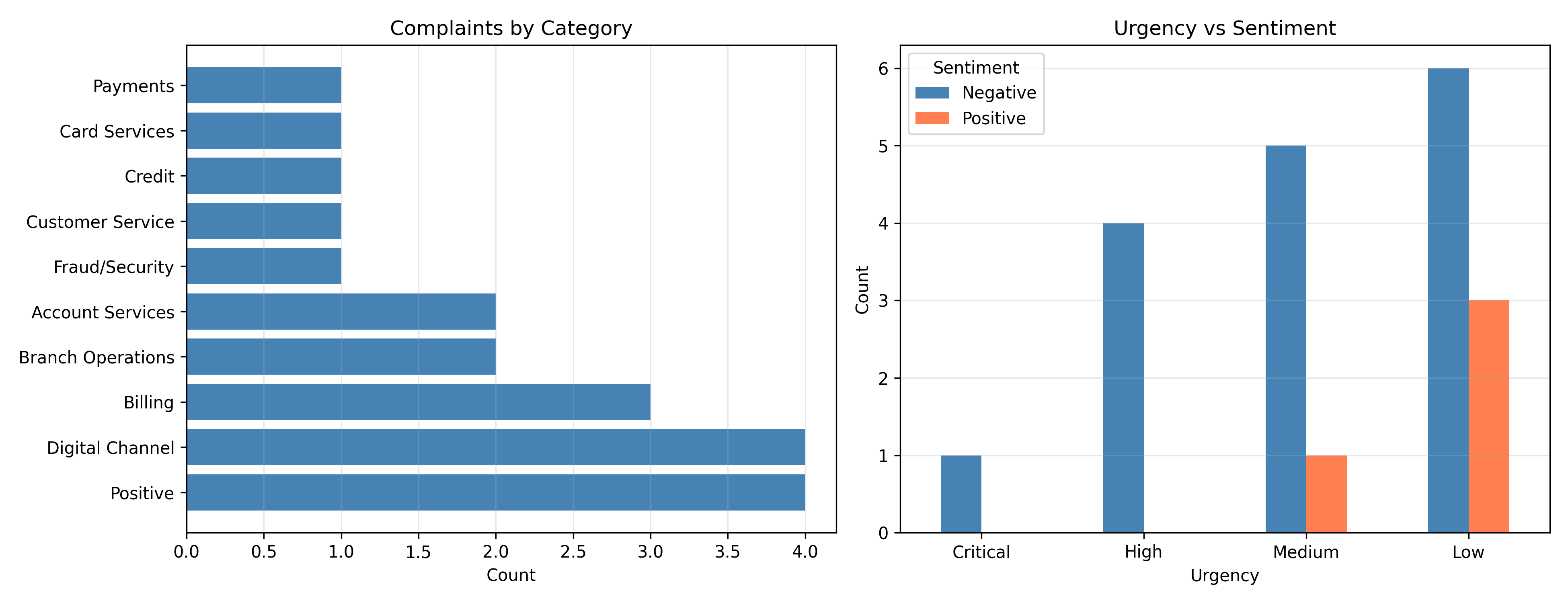
62.6 Retrieval-Augmented Generation (RAG)
The biggest practical limitation of LLMs is the knowledge cutoff — they cannot access information beyond their training data. Retrieval-Augmented Generation (RAG) solves this by combining an LLM with a live document search:
- Index your documents as dense vector embeddings
- Retrieve the most relevant chunks when a user asks a question
- Augment the LLM prompt with those retrieved chunks
- Generate a response grounded in your own documents
This makes it possible to build a “question-answering” system over internal reports, policy documents, contracts, or databases — without fine-tuning the LLM.
Show code
library(tidyverse)
# Simulate a simplified RAG pipeline without a live embedding API
# Uses TF-IDF cosine similarity as a proxy for semantic embeddings
# ── Step 1: Knowledge base (internal policy documents) ─────────────────────────
knowledge_base <- tibble(
doc_id = 1:6,
title = c("Credit Policy", "Anti-Money Laundering Guide", "Customer Onboarding",
"Loan Recovery", "Digital Banking FAQ", "Branch Operations Manual"),
content = c(
"Minimum credit score for personal loans is 650. LTV ratio must not exceed 80%. Maximum loan tenure is 5 years for consumer loans.",
"All transactions above ₦5 million must be flagged for manual review. KYC documents must be verified within 48 hours of account opening.",
"New customers must provide BVN, valid ID, and proof of address. Remote onboarding via the app requires a selfie verification.",
"Accounts 90+ days past due are classified as non-performing. Recovery agents may be engaged after 120 days of non-payment.",
"The mobile app supports USSD fallback on all major networks. Transfers above ₦1 million require a soft token OTP.",
"Branch operational hours are 8am–4pm Monday to Friday. Cash deposit limits are ₦500,000 per day at the counter."
)
)
# ── Step 2: TF-IDF similarity (proxy for embedding similarity) ─────────────────
compute_tfidf_similarity <- function(query, documents) {
# Simple word-overlap cosine similarity (approximate embedding proxy)
query_words <- str_split(str_to_lower(query), "\\W+")[[1]]
query_words <- query_words[nchar(query_words) > 2]
similarities <- map_dbl(documents, function(doc) {
doc_words <- str_split(str_to_lower(doc), "\\W+")[[1]]
doc_words <- doc_words[nchar(doc_words) > 2]
common <- length(intersect(query_words, doc_words))
common / sqrt(length(query_words) * length(doc_words) + 0.01)
})
similarities
}
# ── Step 3: RAG retrieval ──────────────────────────────────────────────────────
rag_retrieve <- function(query, kb, top_k = 2) {
sims <- compute_tfidf_similarity(query, kb$content)
kb |>
mutate(similarity = round(sims, 3)) |>
arrange(desc(similarity)) |>
head(top_k)
}
# ── Demo queries ────────────────────────────────────────────────────────────────
queries <- c(
"What documents are needed to open an account?",
"What is the maximum loan-to-value ratio?",
"How are large transactions handled for compliance?"
)
cat("=== RAG Retrieval Demonstration ===\n\n")
#> === RAG Retrieval Demonstration ===
for (q in queries) {
cat("Query: \"", q, "\"\n", sep = "")
retrieved <- rag_retrieve(q, knowledge_base)
cat("Top retrieved documents:\n")
for (i in 1:nrow(retrieved)) {
cat(" [", retrieved$doc_id[i], "] ", retrieved$title[i],
" (similarity: ", retrieved$similarity[i], ")\n", sep = "")
}
cat("\nAugmented prompt snippet:\n")
cat(" Context: \"", str_trunc(retrieved$content[1], 100), "\"\n")
cat(" Question:", q, "\n\n")
cat("------\n\n")
}
#> Query: "What documents are needed to open an account?"
#> Top retrieved documents:
#> [2] Anti-Money Laundering Guide (similarity: 0.198)
#> [4] Loan Recovery (similarity: 0.099)
#>
#> Augmented prompt snippet:
#> Context: " All transactions above ₦5 million must be flagged for manual review. KYC documents must be verifi... "
#> Question: What documents are needed to open an account?
#>
#> ------
#>
#> Query: "What is the maximum loan-to-value ratio?"
#> Top retrieved documents:
#> [1] Credit Policy (similarity: 0.281)
#> [5] Digital Banking FAQ (similarity: 0.102)
#>
#> Augmented prompt snippet:
#> Context: " Minimum credit score for personal loans is 650. LTV ratio must not exceed 80%. Maximum loan tenur... "
#> Question: What is the maximum loan-to-value ratio?
#>
#> ------
#>
#> Query: "How are large transactions handled for compliance?"
#> Top retrieved documents:
#> [2] Anti-Money Laundering Guide (similarity: 0.183)
#> [4] Loan Recovery (similarity: 0.092)
#>
#> Augmented prompt snippet:
#> Context: " All transactions above ₦5 million must be flagged for manual review. KYC documents must be verifi... "
#> Question: How are large transactions handled for compliance?
#>
#> ------Show code
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Knowledge base
knowledge_base = pd.DataFrame({
'doc_id': range(1, 7),
'title': [
"Credit Policy", "Anti-Money Laundering Guide", "Customer Onboarding",
"Loan Recovery", "Digital Banking FAQ", "Branch Operations Manual"
],
'content': [
"Minimum credit score for personal loans is 650. LTV ratio must not exceed 80%. Maximum loan tenure is 5 years.",
"All transactions above 5 million naira must be flagged for manual review. KYC documents must be verified within 48 hours.",
"New customers must provide BVN, valid ID, and proof of address. Remote onboarding requires selfie verification.",
"Accounts 90 days past due are classified as non-performing. Recovery agents may be engaged after 120 days.",
"The mobile app supports USSD fallback on all major networks. Transfers above 1 million require OTP.",
"Branch hours are 8am to 4pm Monday to Friday. Cash deposit limits are 500000 naira per day."
]
})
# Build TF-IDF index
vectorizer = TfidfVectorizer(stop_words='english')
doc_vectors = vectorizer.fit_transform(knowledge_base['content'])
def rag_retrieve(query, top_k=2):
query_vec = vectorizer.transform([query])
sims = cosine_similarity(query_vec, doc_vectors).flatten()
top_idx = sims.argsort()[::-1][:top_k]
result = knowledge_base.iloc[top_idx].copy()
result['similarity'] = sims[top_idx].round(3)
return result
queries = [
"What documents are needed to open an account?",
"What is the maximum loan-to-value ratio?",
"How are large transactions handled for compliance?"
]
print("=== RAG Retrieval Demonstration ===\n")
#> === RAG Retrieval Demonstration ===
for q in queries:
print(f'Query: "{q}"')
retrieved = rag_retrieve(q)
for _, row in retrieved.iterrows():
print(f" [{row['doc_id']}] {row['title']} (similarity: {row['similarity']:.3f})")
print(f" Context snippet: \"{retrieved.iloc[0]['content'][:80]}...\"")
print()
#> Query: "What documents are needed to open an account?"
#> [2] Anti-Money Laundering Guide (similarity: 0.316)
#> [6] Branch Operations Manual (similarity: 0.000)
#> Context snippet: "All transactions above 5 million naira must be flagged for manual review. KYC do..."
#>
#> Query: "What is the maximum loan-to-value ratio?"
#> [1] Credit Policy (similarity: 0.463)
#> [6] Branch Operations Manual (similarity: 0.000)
#> Context snippet: "Minimum credit score for personal loans is 650. LTV ratio must not exceed 80%. M..."
#>
#> Query: "How are large transactions handled for compliance?"
#> [2] Anti-Money Laundering Guide (similarity: 0.316)
#> [6] Branch Operations Manual (similarity: 0.000)
#> Context snippet: "All transactions above 5 million naira must be flagged for manual review. KYC do..."62.7 Evaluating LLM Outputs
LLMs hallucinate. They generate confident, fluent, plausible-sounding text that is factually wrong. For business analytics use, systematic evaluation is non-negotiable.
62.7.1 Hallucination and Faithfulness
| Evaluation Type | What It Measures | How to Test |
|---|---|---|
| Faithfulness | Does the output stay true to source documents? | Compare LLM answer to retrieved context |
| Answer relevance | Does the response actually address the question? | Human or automated relevance scoring |
| Factual accuracy | Is the numerical/factual content correct? | Cross-check against a ground-truth database |
| Consistency | Does the model give the same answer to rephrasings? | Ask the same question 5 ways |
Show code
library(tidyverse)
# Simulate an LLM evaluation framework
set.seed(2938)
# Ground-truth answers for a banking FAQ
ground_truth <- tibble(
question = c(
"What is the minimum credit score for a personal loan?",
"How many days before an account is classified as NPL?",
"What is the maximum LTV ratio?",
"How long do KYC verifications take?"
),
correct_answer = c("650", "90 days", "80%", "48 hours")
)
# Simulated LLM responses (some correct, some hallucinated)
llm_responses <- tibble(
question = ground_truth$question,
response = c(
"The minimum credit score required for a personal loan is 650.", # Correct
"Accounts that are 90 days past due are classified as non-performing.", # Correct
"The maximum LTV ratio for consumer lending is 70%.", # Wrong (should be 80%)
"KYC documents must be verified within 24 hours." # Wrong (should be 48 hours)
)
)
# Evaluate: check if correct answer appears in LLM response
evaluation <- ground_truth |>
left_join(llm_responses, by = "question") |>
mutate(
is_correct = str_detect(str_to_lower(response), str_to_lower(correct_answer)),
evaluation = if_else(is_correct, "✓ Correct", "✗ Hallucination")
)
cat("=== LLM Faithfulness Evaluation ===\n\n")
#> === LLM Faithfulness Evaluation ===
print(evaluation |> select(question, correct_answer, response, evaluation))
#> # A tibble: 4 × 4
#> question correct_answer response evaluation
#> <chr> <chr> <chr> <chr>
#> 1 What is the minimum credit score for a per… 650 The min… ✓ Correct
#> 2 How many days before an account is classif… 90 days Account… ✓ Correct
#> 3 What is the maximum LTV ratio? 80% The max… ✗ Halluci…
#> 4 How long do KYC verifications take? 48 hours KYC doc… ✗ Halluci…
accuracy <- mean(evaluation$is_correct)
cat(sprintf("\nOverall accuracy: %d/%d (%.0f%%)\n",
sum(evaluation$is_correct), nrow(evaluation), accuracy * 100))
#>
#> Overall accuracy: 2/4 (50%)
cat("⚠️ Hallucination rate:", sprintf("%.0f%%", (1 - accuracy) * 100), "\n")
#> ⚠️ Hallucination rate: 50%
cat(" Review all LLM outputs against ground-truth sources before use.\n")
#> Review all LLM outputs against ground-truth sources before use.Show code
import pandas as pd
# Ground-truth answers
ground_truth = pd.DataFrame({
'question': [
"What is the minimum credit score for a personal loan?",
"How many days before an account is classified as NPL?",
"What is the maximum LTV ratio?",
"How long do KYC verifications take?"
],
'correct': ["650", "90", "80%", "48 hours"]
})
# Simulated LLM responses
llm_responses = pd.DataFrame({
'question': ground_truth['question'],
'response': [
"The minimum credit score required for a personal loan is 650.",
"Accounts that are 90 days past due are classified as non-performing.",
"The maximum LTV ratio for consumer lending is 70%.", # Wrong
"KYC documents must be verified within 24 hours." # Wrong
]
})
evaluation = ground_truth.merge(llm_responses, on='question')
evaluation['correct_in_response'] = evaluation.apply(
lambda r: r['correct'].lower() in r['response'].lower(), axis=1
)
evaluation['verdict'] = evaluation['correct_in_response'].map({True: '✓ Correct', False: '✗ Hallucination'})
print("=== LLM Faithfulness Evaluation ===")
#> === LLM Faithfulness Evaluation ===
for _, row in evaluation.iterrows():
print(f"\nQ: {row['question']}")
print(f" Expected: {row['correct']}")
print(f" Response: {row['response']}")
print(f" Verdict: {row['verdict']}")
#>
#> Q: What is the minimum credit score for a personal loan?
#> Expected: 650
#> Response: The minimum credit score required for a personal loan is 650.
#> Verdict: ✓ Correct
#>
#> Q: How many days before an account is classified as NPL?
#> Expected: 90
#> Response: Accounts that are 90 days past due are classified as non-performing.
#> Verdict: ✓ Correct
#>
#> Q: What is the maximum LTV ratio?
#> Expected: 80%
#> Response: The maximum LTV ratio for consumer lending is 70%.
#> Verdict: ✗ Hallucination
#>
#> Q: How long do KYC verifications take?
#> Expected: 48 hours
#> Response: KYC documents must be verified within 24 hours.
#> Verdict: ✗ Hallucination
acc = evaluation['correct_in_response'].mean()
print(f"\nAccuracy: {acc*100:.0f}% | Hallucination rate: {(1-acc)*100:.0f}%")
#>
#> Accuracy: 50% | Hallucination rate: 50%62.8 When to Use Generative AI — and When Not To
Generative AI is powerful, but it is not always the right tool. Use the following decision framework:
Show code
library(tidyverse)
framework <- tribble(
~Task, ~`Best Approach`, ~Reason,
"Predict customer churn probability", "Classical ML (XGBoost, Logistic Regression)", "Structured tabular data; interpretability required",
"Summarise 1,000 customer reviews", "LLM (GPT-4o, Claude)", "Unstructured text; nuanced understanding needed",
"Forecast next quarter's revenue", "Time-series model (ARIMA, Prophet)", "Temporal patterns; requires calibrated intervals",
"Answer questions from policy documents", "RAG + LLM", "Knowledge retrieval from internal documents",
"Classify transactions as fraud/not fraud", "Classical ML (Random Forest, XGBoost)", "Requires real-time speed; high precision needed",
"Draft a board report narrative", "LLM with human review", "Creative/language task; human oversight essential",
"Segment customers into groups", "Clustering (K-Means, DBSCAN)", "Unsupervised pattern discovery",
"Extract structured fields from contracts", "LLM (few-shot prompting)", "Semi-structured text requiring entity extraction",
"Detect anomalous sensor readings", "Isolation Forest / statistical methods", "Speed, interpretability, no training text required",
"Build an internal chatbot on HR policy", "RAG + LLM", "Grounded Q&A over specific document corpus"
)
cat("=== When to Use LLMs vs Classical Analytics ===\n\n")
#> === When to Use LLMs vs Classical Analytics ===
print(framework, n = Inf)
#> # A tibble: 10 × 3
#> Task `Best Approach` Reason
#> <chr> <chr> <chr>
#> 1 Predict customer churn probability Classical ML (XGBoost, Logis… Struc…
#> 2 Summarise 1,000 customer reviews LLM (GPT-4o, Claude) Unstr…
#> 3 Forecast next quarter's revenue Time-series model (ARIMA, Pr… Tempo…
#> 4 Answer questions from policy documents RAG + LLM Knowl…
#> 5 Classify transactions as fraud/not fraud Classical ML (Random Forest,… Requi…
#> 6 Draft a board report narrative LLM with human review Creat…
#> 7 Segment customers into groups Clustering (K-Means, DBSCAN) Unsup…
#> 8 Extract structured fields from contracts LLM (few-shot prompting) Semi-…
#> 9 Detect anomalous sensor readings Isolation Forest / statistic… Speed…
#> 10 Build an internal chatbot on HR policy RAG + LLM Groun…62.9 Case Study: AI-Augmented Analyst at a Nigerian FMCG Company
Context: A fast-moving consumer goods company sells products across 12 Nigerian states through a 400-strong sales force. The analytics team receives 200+ weekly reports — sales summaries, competitor intelligence, field agent notes — that were previously unread due to volume.
Solution: A RAG-based internal intelligence system:
- All weekly reports are automatically ingested and embedded
- Analysts query the system in natural language (“Which states had the steepest price increase last week?”)
- The LLM retrieves relevant report sections and synthesises a structured answer
- Results are verified against the source data before action
Show code
library(tidyverse)
set.seed(7193)
# Simulate weekly field agent reports
states <- c("Lagos", "Abuja", "Kano", "Rivers", "Oyo", "Kaduna",
"Anambra", "Delta", "Enugu", "Benue", "Kwara", "Sokoto")
weekly_reports <- expand_grid(state = states, week = 1:4) |>
mutate(
avg_price_index = 100 + rnorm(n(), 0, 5) + (week - 1) * runif(n(), -1, 3),
sales_volume = rpois(n(), lambda = 1000) * (1 + rnorm(n(), 0, 0.1)),
stockout_events = rpois(n(), lambda = 2),
competitor_promo = rbinom(n(), 1, 0.3),
agent_morale = sample(c("High", "Medium", "Low"), n(), replace = TRUE, prob = c(0.5, 0.3, 0.2))
)
# Simulate the kind of insights an LLM-RAG system would extract and return
cat("=== Sample LLM-RAG Query Results ===\n\n")
#> === Sample LLM-RAG Query Results ===
cat("Query: 'Which states had the steepest price increase this week?'\n")
#> Query: 'Which states had the steepest price increase this week?'
price_changes <- weekly_reports |>
filter(week %in% c(3, 4)) |>
group_by(state, week) |>
summarise(avg_price = mean(avg_price_index), .groups = "drop") |>
pivot_wider(names_from = week, values_from = avg_price, names_prefix = "wk") |>
mutate(change = wk4 - wk3) |>
arrange(desc(change)) |>
head(5)
cat("Top 5 states by price increase (Wk3 → Wk4):\n")
#> Top 5 states by price increase (Wk3 → Wk4):
print(price_changes |> select(state, wk3, wk4, change) |>
mutate(across(wk3:change, round, 1)))
#> # A tibble: 5 × 4
#> state wk3 wk4 change
#> <chr> <dbl> <dbl> <dbl>
#> 1 Rivers 93.1 109. 15.5
#> 2 Kaduna 102. 112. 10.4
#> 3 Delta 99.3 109 9.6
#> 4 Kano 104. 113. 9
#> 5 Anambra 99.1 107. 8.2
cat("\nQuery: 'Where are stockouts and competitor promotions co-occurring?'\n")
#>
#> Query: 'Where are stockouts and competitor promotions co-occurring?'
hotspots <- weekly_reports |>
filter(week == 4, stockout_events >= 2, competitor_promo == 1) |>
arrange(desc(stockout_events)) |>
select(state, stockout_events)
if (nrow(hotspots) > 0) {
print(hotspots)
} else {
cat(" No critical hotspots identified this week.\n")
}
#> # A tibble: 4 × 2
#> state stockout_events
#> <chr> <int>
#> 1 Kano 5
#> 2 Lagos 3
#> 3 Anambra 2
#> 4 Benue 2
cat("\nQuery: 'Summarise agent morale across regions'\n")
#>
#> Query: 'Summarise agent morale across regions'
morale_summary <- weekly_reports |>
filter(week == 4) |>
count(agent_morale) |>
mutate(pct = round(100 * n / sum(n), 1))
print(morale_summary)
#> # A tibble: 3 × 3
#> agent_morale n pct
#> <chr> <int> <dbl>
#> 1 High 4 33.3
#> 2 Low 4 33.3
#> 3 Medium 4 33.3Show code
import pandas as pd
import numpy as np
np.random.seed(7193)
states = ["Lagos", "Abuja", "Kano", "Rivers", "Oyo", "Kaduna",
"Anambra", "Delta", "Enugu", "Benue", "Kwara", "Sokoto"]
rows = []
for state in states:
for week in range(1, 5):
rows.append({
'state': state,
'week': week,
'avg_price_index': 100 + np.random.normal(0, 5) + (week - 1) * np.random.uniform(-1, 3),
'sales_volume': int(np.random.poisson(1000) * (1 + np.random.normal(0, 0.1))),
'stockout_events': np.random.poisson(2),
'competitor_promo': np.random.binomial(1, 0.3),
'agent_morale': np.random.choice(['High', 'Medium', 'Low'], p=[0.5, 0.3, 0.2])
})
reports = pd.DataFrame(rows)
print("=== Sample LLM-RAG Query Results ===\n")
#> === Sample LLM-RAG Query Results ===
print("Query: 'Which states had the steepest price increase this week?'")
#> Query: 'Which states had the steepest price increase this week?'
price_pivot = reports[reports['week'].isin([3, 4])].groupby(['state', 'week'])['avg_price_index'].mean().unstack()
price_pivot.columns = ['wk3', 'wk4']
price_pivot['change'] = price_pivot['wk4'] - price_pivot['wk3']
top5 = price_pivot.sort_values('change', ascending=False).head(5).round(1)
print(top5)
#> wk3 wk4 change
#> state
#> Sokoto 90.8 112.6 21.7
#> Benue 99.4 112.7 13.3
#> Enugu 100.5 111.3 10.7
#> Anambra 97.6 105.9 8.3
#> Kaduna 97.9 105.9 8.0
print("\nQuery: 'Where are stockouts and competitor promotions co-occurring?'")
#>
#> Query: 'Where are stockouts and competitor promotions co-occurring?'
wk4 = reports[reports['week'] == 4]
hotspots = wk4[(wk4['stockout_events'] >= 2) & (wk4['competitor_promo'] == 1)]
if len(hotspots) > 0:
print(hotspots[['state', 'stockout_events']].sort_values('stockout_events', ascending=False).to_string(index=False))
else:
print(" No critical hotspots identified this week.")
#> state stockout_events
#> Kano 5
#> Kwara 4
#> Enugu 2
print("\nQuery: 'Summarise agent morale this week'")
#>
#> Query: 'Summarise agent morale this week'
morale = wk4['agent_morale'].value_counts()
for level, cnt in morale.items():
print(f" {level}: {cnt} states ({cnt/len(wk4)*100:.0f}%)")
#> High: 7 states (58%)
#> Medium: 3 states (25%)
#> Low: 2 states (17%)62.10 Chapter Exercises
Chapter 57 Exercises
Exercise 57.1: Understanding What LLMs Are and Are Not
A student says: “ChatGPT knows everything because it was trained on the entire internet.” Identify and correct three specific misconceptions in this statement. For each, explain what is actually true.
Explain the difference between training an LLM and fine-tuning one. Use the analogy of a university-educated professional who then undergoes specialist training (e.g., a doctor who specialises in cardiology).
The “context window” limits how much text an LLM can process at once. A document is 200 pages long but the model’s context window fits only 30 pages. Describe two practical strategies for processing the full document with a limited context window.
An LLM confidently states: “The inflation rate in Nigeria in Q3 2025 was 18.4%.” How would you verify this claim? What general strategy should you always apply when an LLM gives you a specific numeric fact?
Give three business tasks where LLMs are genuinely useful today, and three tasks where classical machine learning (e.g., XGBoost, logistic regression) would be more appropriate. Justify each choice.
Exercise 57.2: Prompt Engineering in Practice
Write improved versions of the following weak prompts. For each, explain what was wrong with the original and why your version is better.
Weak: “Summarise this report.”
Context: You have a 40-page annual report from a Nigerian commercial bank and need a 3-bullet summary for the Board of Directors.Weak: “Write a marketing email.”
Context: You are launching a new savings product targeting young professionals aged 25–35 in Lagos. The offer is a 12% annual interest rate.Weak: “Is this a good investment?”
Context: You want to evaluate whether to invest ₦5 million in a solar energy startup.Weak: “What should I do about my unhappy customer?”
Context: A customer called to complain that their loan application was rejected without explanation.For prompt (b) above, write a few-shot prompt that includes two examples of good marketing emails (one for a different product) to guide the LLM’s style and tone.
Exercise 57.3: RAG Architecture Design
A major Nigerian law firm wants to build an internal question-answering system. Associates often spend hours searching through thousands of past case files, client contracts, and legal precedents.
Explain why a simple LLM (without RAG) would be inadequate for this task. Name at least three specific problems that would arise.
Describe the RAG architecture in four steps. For each step, explain what happens and why it is necessary. Use the law firm context in your explanation.
The firm’s documents are in multiple formats: Word documents, PDFs, scanned images, and emails. What preprocessing challenge does each format present? Suggest a specific tool or approach for handling each.
A junior associate asks the system: “What was the outcome in our case against Dangote Steel in 2019?” The system retrieves three relevant document chunks but the answer is not explicitly stated — it must be inferred from the retrieved context. What is the risk in this situation, and how would you mitigate it?
The firm’s Managing Partner says: “We cannot let a system make claims about our cases without being able to trace where the information came from.” Design a citation mechanism for the RAG system that satisfies this requirement. What would the system’s output look like?
Exercise 57.4: Evaluating LLM Outputs
You are building an internal HR chatbot for a multinational company operating in Nigeria. The bot answers employee questions about leave policy, benefits, and HR procedures. After deployment, you need to monitor its quality.
Define hallucination in the context of LLMs. Give a specific example of a hallucination that would be particularly harmful in an HR chatbot.
Design a ground-truth evaluation dataset for this HR chatbot. How many questions would you include? How would you create the reference answers? Who should write them?
Define three evaluation dimensions (other than factual accuracy) that matter for an HR chatbot. For each, write a specific test question and describe how you would evaluate the response.
The system’s responses are 85% factually accurate in initial testing. After 6 months, employees report it gives wrong answers about the newly updated parental leave policy. What likely happened? What monitoring process would have caught this earlier?
Some HR questions are sensitive: “My manager is harassing me.” “I think my colleague is being overpaid.” Design guidelines for which questions the chatbot should decline to answer and how it should respond when declining.
Exercise 57.5: Capstone — LLM Business Case
You are an Analytics Manager at a large Nigerian commercial bank. The CEO has asked you to evaluate whether the bank should invest in LLM-powered tools. Present a business case covering:
Identify three specific use cases where LLMs could save time or reduce costs for the bank. For each use case, estimate: (i) how many hours per week the task currently takes; (ii) the percentage of that time LLMs could handle autonomously; (iii) the tasks that must still involve a human.
Identify three specific risks of deploying LLMs in a Nigerian bank context. For each risk, describe one mitigation strategy.
The bank’s IT security team raises concerns about sending customer data to external LLM APIs (like OpenAI). Describe two alternative architectural approaches that would address this data privacy concern.
The bank currently uses classical ML models for credit decisions. A technology vendor proposes replacing these with an LLM-based system. Write a one-paragraph response evaluating this proposal, addressing: (i) whether LLMs are appropriate for this task; (ii) what regulatory concerns arise; (iii) what you would recommend instead.
Write a 250-word executive summary of your LLM business case for the CEO. Recommend whether the bank should invest, at what scale, and what the first deployment should be. Justify your recommendation with evidence from the analysis above. Use plain language.
62.11 Further Reading
Brown, T., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33.
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022.
Anthropic. (2024). Claude’s Model Specification. anthropic.com.
OpenAI. (2024). GPT-4 Technical Report. openai.com.