---
title: "Decision Trees"
---
```{python}
#| label: python-setup-14-decision-trees
#| include: false
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import entropy as scipy_entropy
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import cross_val_score
```
::: {.callout-note icon="false"}
## 📋 Learning Objectives
By the end of this chapter, you will be able to:
- Understand how decision trees make predictions through recursive binary splitting
- Explain the anatomy of a decision tree: root nodes, internal nodes, leaf nodes, and branches
- Compute splitting criteria: information gain, entropy, and Gini impurity
- Implement the CART algorithm and grow a full decision tree
- Interpret decision tree predictions and feature importance
- Identify and correct overfitting through cost-complexity pruning
- Explain the strengths and limitations of decision trees for business problems
- Present tree-based decisions to non-technical stakeholders
:::
## The Decision Tree Metaphor
A decision tree is a **flowchart** that asks a series of yes/no questions to reach a final decision. Imagine a bank manager deciding whether to approve a loan:
"Is the applicant's annual income above ₦5 million?" → Yes → Next question
"Is their debt-to-income ratio below 0.4?" → Yes → Approve
"Has the applicant been employed for at least 2 years?" → Yes → Approve
"No?" → Reject
This intuitive process of asking sequential binary questions is exactly what a decision tree does. Each question **partitions the data** into smaller subsets, and we repeat until we reach a **pure** subset (all yes, all no) or stop by rule.
::: {.callout-note icon="false"}
## 📘 Theory: Anatomy of a Decision Tree
**Nodes:**
- **Root node:**
The top node where all data starts. It asks the first question.
- **Internal nodes:**
Intermediate nodes that ask splitting questions. Each has one parent and two children.
- **Leaf nodes:**
Terminal nodes with no children. They assign a final class or prediction (e.g., "Approve", "Reject", "Fraud").
**Edges (Branches):**
- Each branch represents the outcome of a yes/no question (left for "no," right for "yes").
- Every path from root to leaf defines a **decision rule** that can be explained to a non-technical person.
**Why trees are interpretable:**
A single prediction path reads like:
"Customer has income > ₦10M AND has existing account AND has zero defaults → Approved."
This is far more transparent than a neural network's 50 hidden layers. Decision trees satisfy regulatory demands (especially in financial services) to explain decisions to customers.
:::
### Reading a Decision Tree
::: {.callout-caution icon="false"}
## 📝 Section 14.1 Review Questions
1. What is the relationship between a decision tree flowchart and a bank manager's loan approval process?
2. Define root node, internal node, and leaf node. What does each do?
3. How does a decision rule in a tree translate into a customer-facing explanation?
4. Why do regulators prefer decision trees over black-box models like neural networks?
:::
## Splitting Criteria: Information Gain and Gini Impurity
The core question is: **Which feature and threshold should we use to split at each node?** We need a criterion that measures how much **purer** the resulting child nodes are compared to the parent.
::: {.callout-note icon="false"}
## 📘 Theory: Impurity Measures
**Entropy (Information Gain):**
Entropy measures the disorder in a node. A node is **pure** if all samples belong to one class; **impure** if samples are mixed.
$$H(S) = -\sum_{i=1}^{C} p_i \log_2(p_i)$$
where $p_i$ is the fraction of samples of class $i$ in set $S$, and $C$ is the number of classes.
**Properties:**
- H(S) = 0 if all samples are one class (pure).
- H(S) is maximum when all classes are equally represented (maximum uncertainty).
- For binary classification: $H = -p \log_2(p) - (1-p) \log_2(1-p)$, maximized at p = 0.5.
**Information Gain (IG):**
IG measures the reduction in entropy after a split. A split on feature $X_j$ at threshold $t$ divides set $S$ into $S_L$ (left, X_j ≤ t) and $S_R$ (right, X_j > t).
$$IG(S, X_j, t) = H(S) - \frac{|S_L|}{|S|} H(S_L) - \frac{|S_R|}{|S|} H(S_R)$$
We choose the split that **maximizes IG**.
**Gini Impurity:**
An alternative impurity measure, particularly popular in CART (Classification And Regression Trees):
$$Gini(S) = 1 - \sum_{i=1}^{C} p_i^2$$
Gini ranges from 0 (pure) to 1 − 1/C (maximum impurity). For binary: $Gini = 2p(1-p)$.
**IG vs. Gini:**
- Both lead to similar trees in practice.
- Gini is faster to compute (no logarithms).
- IG is more interpretable (measured in bits).
- Gini is used by scikit-learn's DecisionTreeClassifier by default.
**For regression trees:**
Instead of entropy, we use **variance reduction**. At each node, compute the within-group variance of y values. A split is good if it reduces the weighted variance in the children.
$$\text{Var}_{reduction} = Var(S) - \frac{|S_L|}{|S|} Var(S_L) - \frac{|S_R|}{|S|} Var(S_R)$$
:::
::: {.callout-tip icon="false"}
## 🔑 Key Formula: Information Gain and Gini
**Entropy:**
$$H(S) = -\sum_{i=1}^{C} p_i \log_2(p_i)$$
**Gini Impurity:**
$$Gini(S) = 1 - \sum_{i=1}^{C} p_i^2$$
**Information Gain (entropy-based):**
$$IG(S, X_j, t) = H(S) - \frac{|S_L|}{|S|} H(S_L) - \frac{|S_R|}{|S|} H(S_R)$$
**Variance Reduction (regression):**
$$VarRed(S, X_j, t) = Var(S) - \frac{|S_L|}{|S|} Var(S_L) - \frac{|S_R|}{|S|} Var(S_R)$$
:::
### Computing Gini and Entropy by Hand
Let's work through a simple example. Suppose we have 10 insurance claims:
- 7 are legitimate (class 0)
- 3 are fraudulent (class 1)
**Parent node entropy:**
$$H = -0.7 \log_2(0.7) - 0.3 \log_2(0.3) = -0.7(−0.515) - 0.3(−1.737) = 0.361 + 0.521 = 0.882$$
**Parent node Gini:**
$$Gini = 1 - (0.7)^2 - (0.3)^2 = 1 - 0.49 - 0.09 = 0.42$$
Now suppose we split on **claim_amount ≤ ₦500,000**:
- **Left (≤ ₦500k):** 6 samples: 5 legitimate, 1 fraudulent
- **Right (> ₦500k):** 4 samples: 2 legitimate, 2 fraudulent
**Left entropy:** $H_L = -\frac{5}{6}\log_2(\frac{5}{6}) - \frac{1}{6}\log_2(\frac{1}{6}) = 0.277 + 0.389 = 0.666$
**Right entropy:** $H_R = -0.5 \log_2(0.5) - 0.5 \log_2(0.5) = 1.0$
**Information gain:**
$$IG = 0.882 - \frac{6}{10}(0.666) - \frac{4}{10}(1.0) = 0.882 - 0.400 - 0.400 = 0.082$$
This split reduces impurity by 0.082 bits.
::: {.panel-tabset}
## R
```{r}
library(tidyverse)
# Function to compute entropy
entropy <- function(p) {
p <- p[p > 0 & p < 1] # Remove 0s and 1s to avoid log(0)
-sum(p * log2(p))
}
# Function to compute Gini
gini <- function(p) {
1 - sum(p^2)
}
# Example: 10 claims, 7 legitimate, 3 fraudulent
class_counts <- c(7, 3)
total <- sum(class_counts)
p <- class_counts / total
cat("Parent node:\n")
cat("Entropy:", entropy(p), "\n")
cat("Gini:", gini(p), "\n\n")
# After split on claim_amount <= 500,000
left_counts <- c(5, 1) # 5 legitimate, 1 fraudulent
right_counts <- c(2, 2) # 2 legitimate, 2 fraudulent
left_p <- left_counts / sum(left_counts)
right_p <- right_counts / sum(right_counts)
left_ent <- entropy(left_p)
right_ent <- entropy(right_p)
left_gini <- gini(left_p)
right_gini <- gini(right_p)
parent_ent <- entropy(p)
parent_gini <- gini(p)
# Weighted entropy and Gini after split
weighted_ent <- (6/10) * left_ent + (4/10) * right_ent
weighted_gini <- (6/10) * left_gini + (4/10) * right_gini
cat("After split on claim_amount <= 500,000:\n")
cat("Left child (n=6): Entropy =", round(left_ent, 3), ", Gini =", round(left_gini, 3), "\n")
cat("Right child (n=4): Entropy =", round(right_ent, 3), ", Gini =", round(right_gini, 3), "\n\n")
cat("Information Gain (Entropy):", round(parent_ent - weighted_ent, 3), "\n")
cat("Gini Gain:", round(parent_gini - weighted_gini, 3), "\n")
```
## Python
```{python}
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy(class_counts):
"""Compute entropy given class counts."""
total = np.sum(class_counts)
p = class_counts / total
# Entropy in bits (log2)
ent = -np.sum(p[p > 0] * np.log2(p[p > 0]))
return ent
def compute_gini(class_counts):
"""Compute Gini impurity given class counts."""
total = np.sum(class_counts)
p = class_counts / total
gini = 1 - np.sum(p**2)
return gini
# Parent node: 7 legitimate, 3 fraudulent
parent_counts = np.array([7, 3])
parent_ent = compute_entropy(parent_counts)
parent_gini = compute_gini(parent_counts)
print("Parent node:")
print(f" Entropy: {parent_ent:.4f}")
print(f" Gini: {parent_gini:.4f}\n")
# Split: claim_amount <= 500,000
left_counts = np.array([5, 1]) # 5 legitimate, 1 fraudulent
right_counts = np.array([2, 2]) # 2 legitimate, 2 fraudulent
left_ent = compute_entropy(left_counts)
right_ent = compute_entropy(right_counts)
left_gini = compute_gini(left_counts)
right_gini = compute_gini(right_counts)
n_left = np.sum(left_counts)
n_right = np.sum(right_counts)
n_total = n_left + n_right
weighted_ent = (n_left / n_total) * left_ent + (n_right / n_total) * right_ent
weighted_gini = (n_left / n_total) * left_gini + (n_right / n_total) * right_gini
ig = parent_ent - weighted_ent
gini_gain = parent_gini - weighted_gini
print("After split on claim_amount <= 500,000:")
print(f" Left (n={n_left}): Entropy={left_ent:.4f}, Gini={left_gini:.4f}")
print(f" Right (n={n_right}): Entropy={right_ent:.4f}, Gini={right_gini:.4f}\n")
print(f"Information Gain (Entropy-based): {ig:.4f}")
print(f"Gini Gain: {gini_gain:.4f}")
```
:::
::: {.callout-caution icon="false"}
## 📝 Section 14.2 Review Questions
1. Why is entropy 0 at a leaf node with all samples of one class?
2. Compute entropy and Gini for a node with 100 samples: 50 class A, 50 class B.
3. If a split results in IG = 0.05 bits, is this a good or bad split? How do you decide?
4. For regression trees, what impurity measure replaces entropy?
5. Given a fraudulent claim is much rarer than legitimate claims, does information gain favour splits that isolate fraud?
:::
## Growing a Full Tree: The CART Algorithm
The **CART (Classification and Regression Trees)** algorithm grows a tree greedily:
1. **Start** with all data at the root node.
2. **For each node**, evaluate all possible binary splits on all features.
3. **Choose** the split that maximizes information gain (or Gini gain for CART).
4. **Recursively apply** steps 2–3 to the resulting child nodes.
5. **Stop** when a stopping criterion is met (e.g., min samples per leaf, max depth, no improvement).
::: {.callout-note icon="false"}
## 📘 Theory: The CART Algorithm
**Algorithm:**
```
function GROW_TREE(S, depth):
if stopping_criterion(S, depth) or is_pure(S):
return LEAF_NODE(majority_class(S))
best_gain = -∞
best_split = None
for each feature j and threshold t:
S_L = {(x, y) ∈ S : x_j ≤ t}
S_R = {(x, y) ∈ S : x_j > t}
gain = INFORMATION_GAIN(S, S_L, S_R)
if gain > best_gain:
best_gain = gain
best_split = (j, t)
S_L, S_R = apply_split(S, best_split)
left_child = GROW_TREE(S_L, depth + 1)
right_child = GROW_TREE(S_R, depth + 1)
return INTERNAL_NODE(best_split, left_child, right_child)
```
**Stopping criteria:**
- **Minimum samples per leaf:** Do not split if either child would have < min_samples_leaf observations.
- **Maximum depth:** Do not split if depth >= max_depth.
- **Minimum impurity decrease:** Do not split if the impurity decrease is < min_impurity_decrease (prevents trivial splits).
- **All samples same class:** Node is pure; cannot improve.
**Choosing thresholds:**
For continuous features, we evaluate all **unique values** in the data. For categorical features, we can:
- One-vs-rest encoding: each category is one side of the split.
- Ordinal encoding: if categories are ordered.
**Why greedy?** CART is a **greedy algorithm**: it makes locally optimal choices at each step. It does not backtrack. This means the final tree may not be globally optimal, but the algorithm is fast and works well in practice.
:::
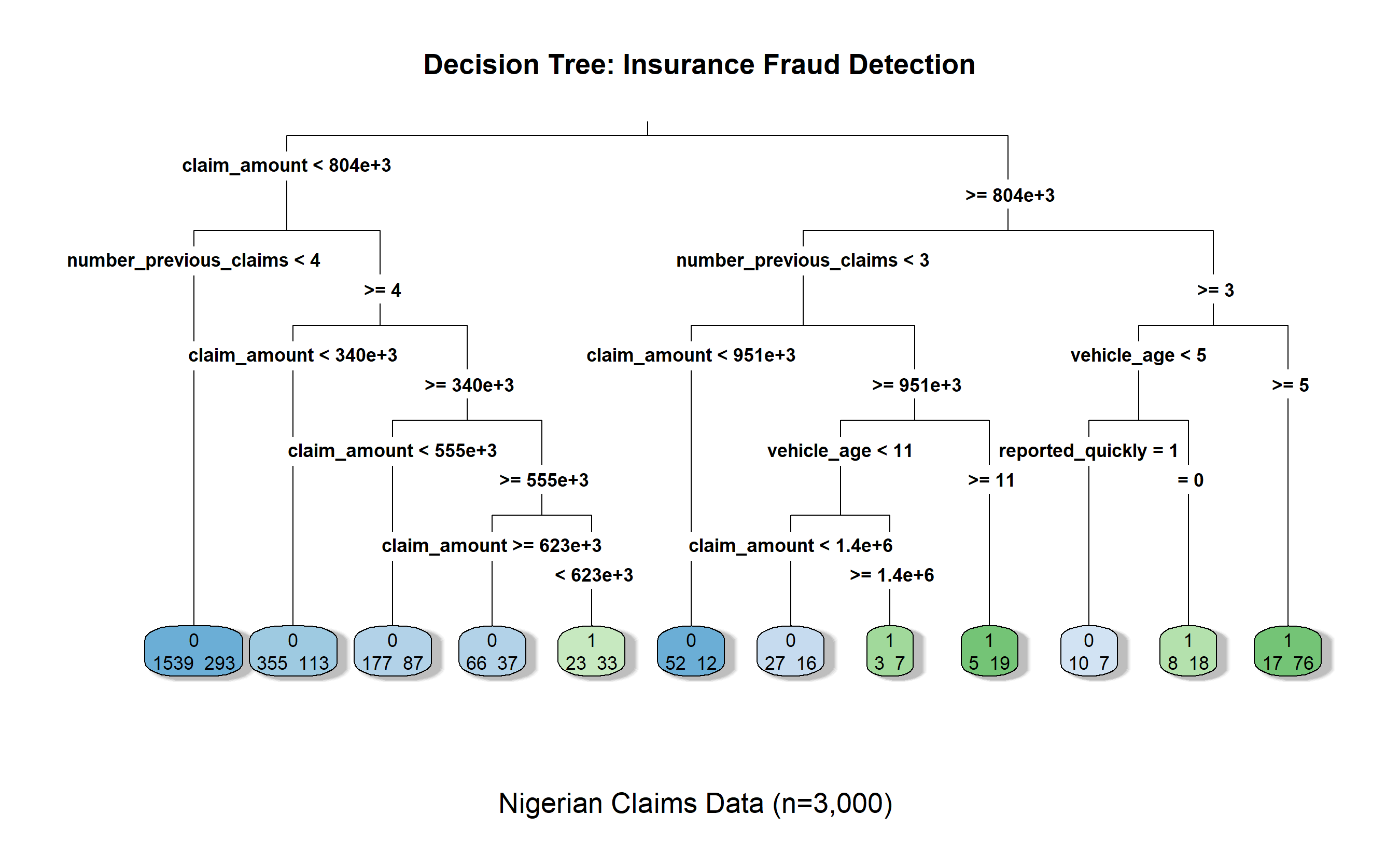
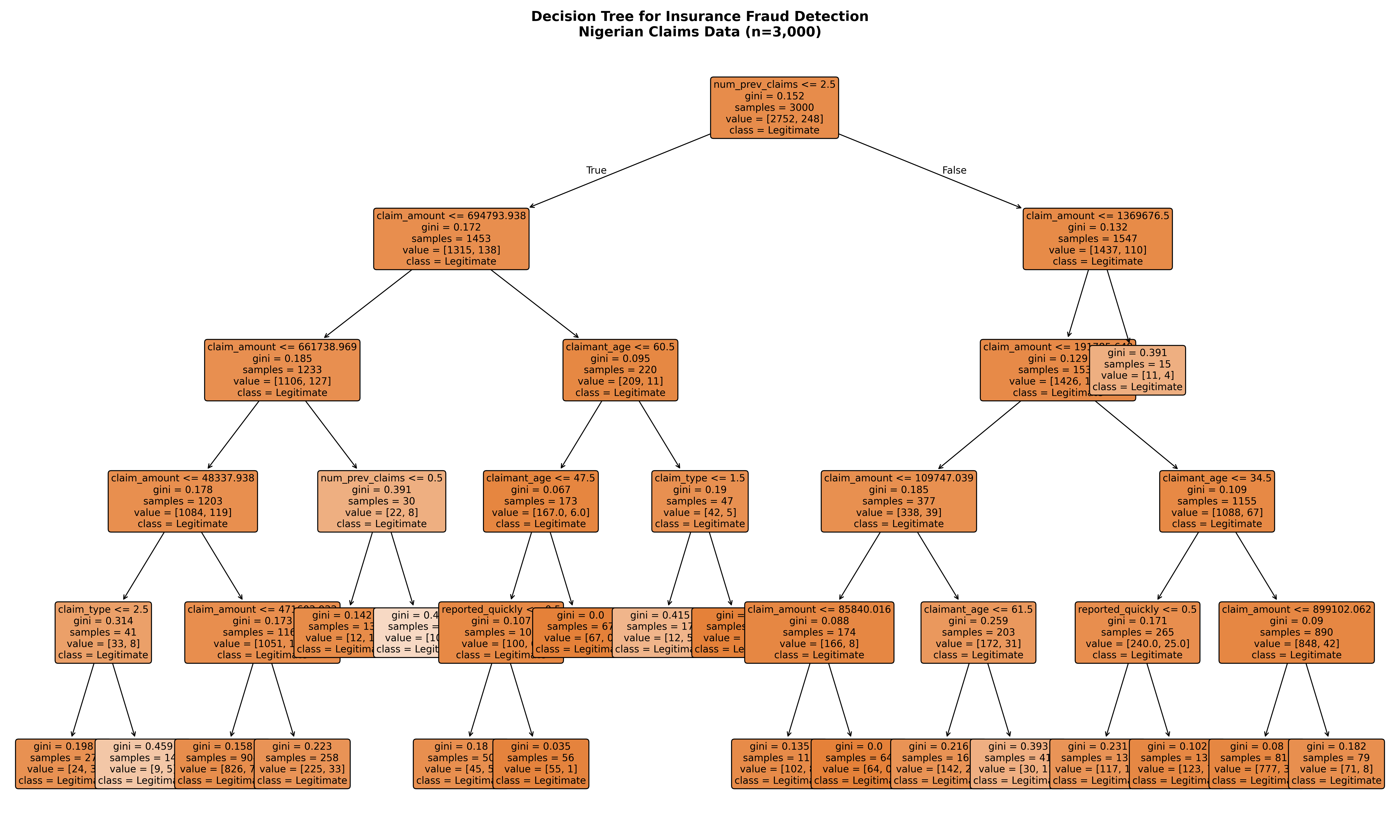
### Case Study: Nigerian Insurance Fraud Detection
We'll build a decision tree on a synthetic dataset of 3,000 insurance claims from Nigeria.
::: {.panel-tabset}
## R
```{r}
library(tidyverse)
library(rpart)
library(rpart.plot)
# Synthetic dataset: Nigerian insurance claims
set.seed(2026)
n_claims <- 3000
# Generate features first, then derive fraud probability from them
fraud_data <- tibble(
claim_id = 1:n_claims,
claim_amount = pmax(rgamma(n_claims, shape = 2, scale = 200000), 10000),
claim_type = sample(c("Vehicle", "Property", "Medical", "Liability"),
n_claims, replace = TRUE,
prob = c(0.5, 0.2, 0.15, 0.15)),
claimant_age = sample(25:70, n_claims, replace = TRUE),
vehicle_age = sample(0:15, n_claims, replace = TRUE),
number_previous_claims = sample(0:5, n_claims, replace = TRUE),
reported_quickly = sample(0:1, n_claims, replace = TRUE) # 1 = within 24 hours
) |>
mutate(
# Fraud probability driven by features so the tree can find real splits
fraud_prob = plogis(-3 + 2e-6 * claim_amount +
0.3 * number_previous_claims -
0.6 * reported_quickly +
0.05 * vehicle_age),
fraud = as.factor(rbinom(n_claims, 1, fraud_prob))
) |>
select(-fraud_prob)
cat("Dataset shape:", nrow(fraud_data), "rows,", ncol(fraud_data), "columns\n")
cat("Fraud class distribution:\n")
print(table(fraud_data$fraud))
# Fit decision tree
dt_model <- rpart(
fraud ~ claim_amount + claim_type + claimant_age + vehicle_age +
number_previous_claims + reported_quickly,
data = fraud_data,
method = "class",
control = rpart.control(minsplit = 20, minbucket = 10, cp = 0.001, maxdepth = 5)
)
cat("\nTree summary:\n")
print(dt_model)
rpart.plot(dt_model, main = "Decision Tree: Insurance Fraud Detection",
sub = "Nigerian Claims Data (n=3,000)",
type = 3, extra = 1, shadow.col = "gray")
## Python
```{python}
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.preprocessing import LabelEncoder
# Synthetic dataset: Nigerian insurance claims
np.random.seed(2026)
n_claims = 3000
fraud_data = pd.DataFrame({
'claim_id': range(1, n_claims + 1),
'claim_amount': np.random.gamma(2, 200000, n_claims),
'claim_type': np.random.choice(
['Vehicle', 'Property', 'Medical', 'Liability'],
n_claims, p=[0.5, 0.2, 0.15, 0.15]
),
'claimant_age': np.random.randint(25, 71, n_claims),
'vehicle_age': np.random.randint(0, 16, n_claims),
'number_previous_claims': np.random.randint(0, 6, n_claims),
'reported_quickly': np.random.randint(0, 2, n_claims),
'fraud': np.random.choice([0, 1], n_claims, p=[0.92, 0.08])
})
fraud_data['claim_amount'] = fraud_data['claim_amount'].clip(lower=10000)
print(f"Dataset shape: {fraud_data.shape}")
print("\nFraud class distribution:")
print(fraud_data['fraud'].value_counts())
# Encode categorical variable
le = LabelEncoder()
fraud_data['claim_type_encoded'] = le.fit_transform(fraud_data['claim_type'])
# Features and target
X = fraud_data[['claim_amount', 'claim_type_encoded', 'claimant_age',
'vehicle_age', 'number_previous_claims', 'reported_quickly']]
y = fraud_data['fraud']
# Fit decision tree
dt_model = DecisionTreeClassifier(
criterion='gini',
min_samples_split=20,
min_samples_leaf=10,
max_depth=5,
random_state=2026
)
dt_model.fit(X, y)
print(f"\nTree depth: {dt_model.get_depth()}")
print(f"Number of leaves: {dt_model.get_n_leaves()}")
# Plot the tree
plt.figure(figsize=(20, 12))
plot_tree(dt_model,
feature_names=['claim_amount', 'claim_type', 'claimant_age',
'vehicle_age', 'num_prev_claims', 'reported_quickly'],
class_names=['Legitimate', 'Fraud'],
filled=True, rounded=True, fontsize=10)
plt.title("Decision Tree for Insurance Fraud Detection\nNigerian Claims Data (n=3,000)",
fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('fraud_tree.png', dpi=100, bbox_inches='tight')
plt.show()
# Feature importance
feature_names = ['claim_amount', 'claim_type', 'claimant_age',
'vehicle_age', 'num_prev_claims', 'reported_quickly']
importances = dt_model.feature_importances_
feature_imp_df = pd.DataFrame({
'Feature': feature_names,
'Importance': importances
}).sort_values('Importance', ascending=False)
print("\nFeature Importance:")
print(feature_imp_df)
```
:::
::: {.callout-caution icon="false"}
## 📝 Section 14.3 Review Questions
1. Explain the greedy nature of the CART algorithm. Why doesn't it guarantee a globally optimal tree?
2. What is the effect of lowering `min_samples_leaf`? Raising `max_depth`?
3. In the fraud dataset, which feature appears at the root node? Why might that be?
4. How would you encode categorical features (e.g., claim_type) for splitting?
5. Why is a minimum impurity decrease (cp) important in CART?
:::
## Reading and Presenting a Decision Tree
Once we grow a tree, we must **interpret it** and **communicate it** to non-technical stakeholders.
::: {.callout-note icon="false"}
## 📘 Theory: Tree Interpretation and Feature Importance
**Reading a single prediction:**
Follow the path from root to leaf. Each node shows:
- **Splitting rule:** "claim_amount ≤ 500,000?" (Yes left, No right)
- **Samples:** How many observations at this node
- **Value:** Class breakdown (e.g., 100 legitimate, 20 fraudulent)
- **Gini/Entropy:** Impurity measure
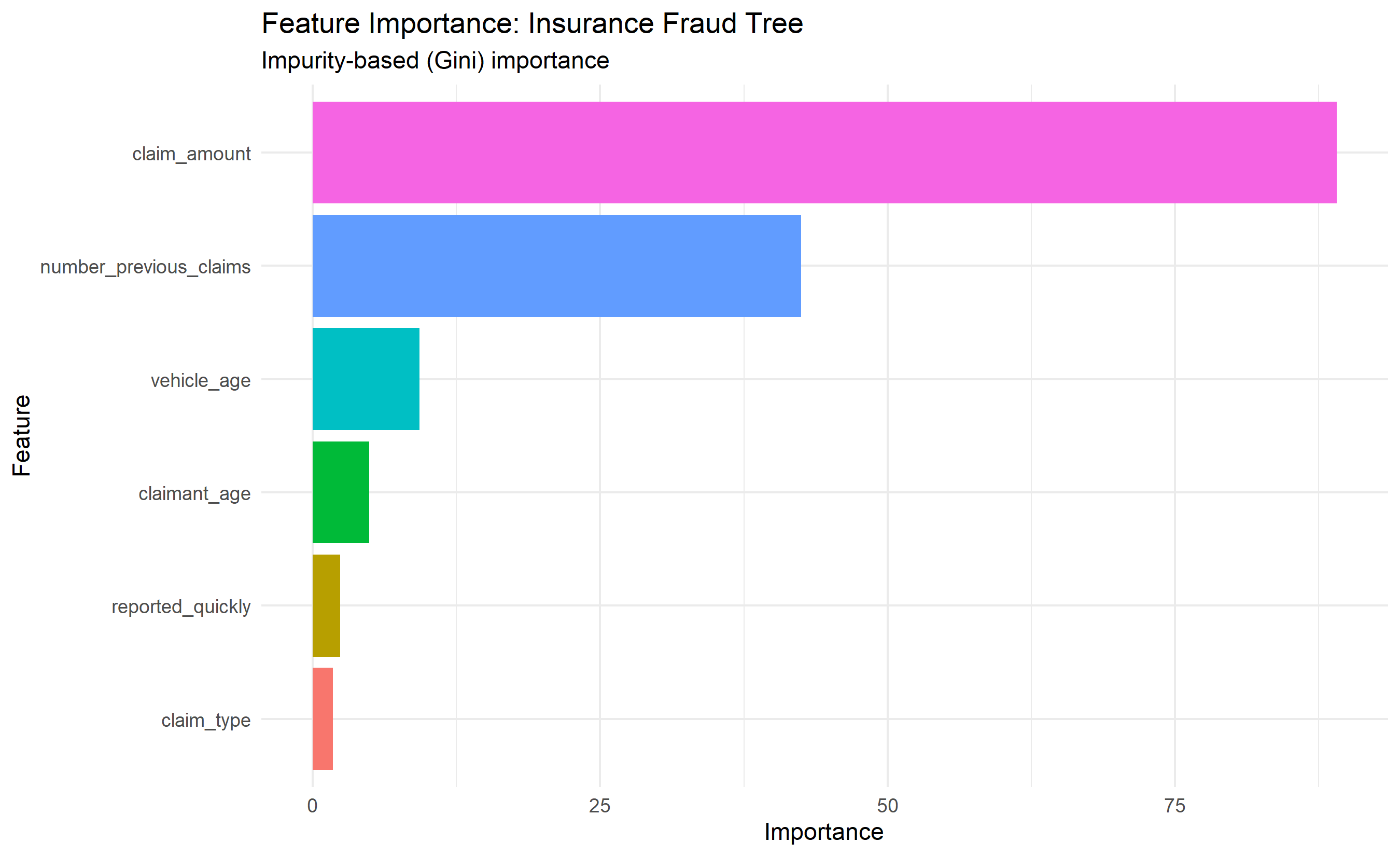
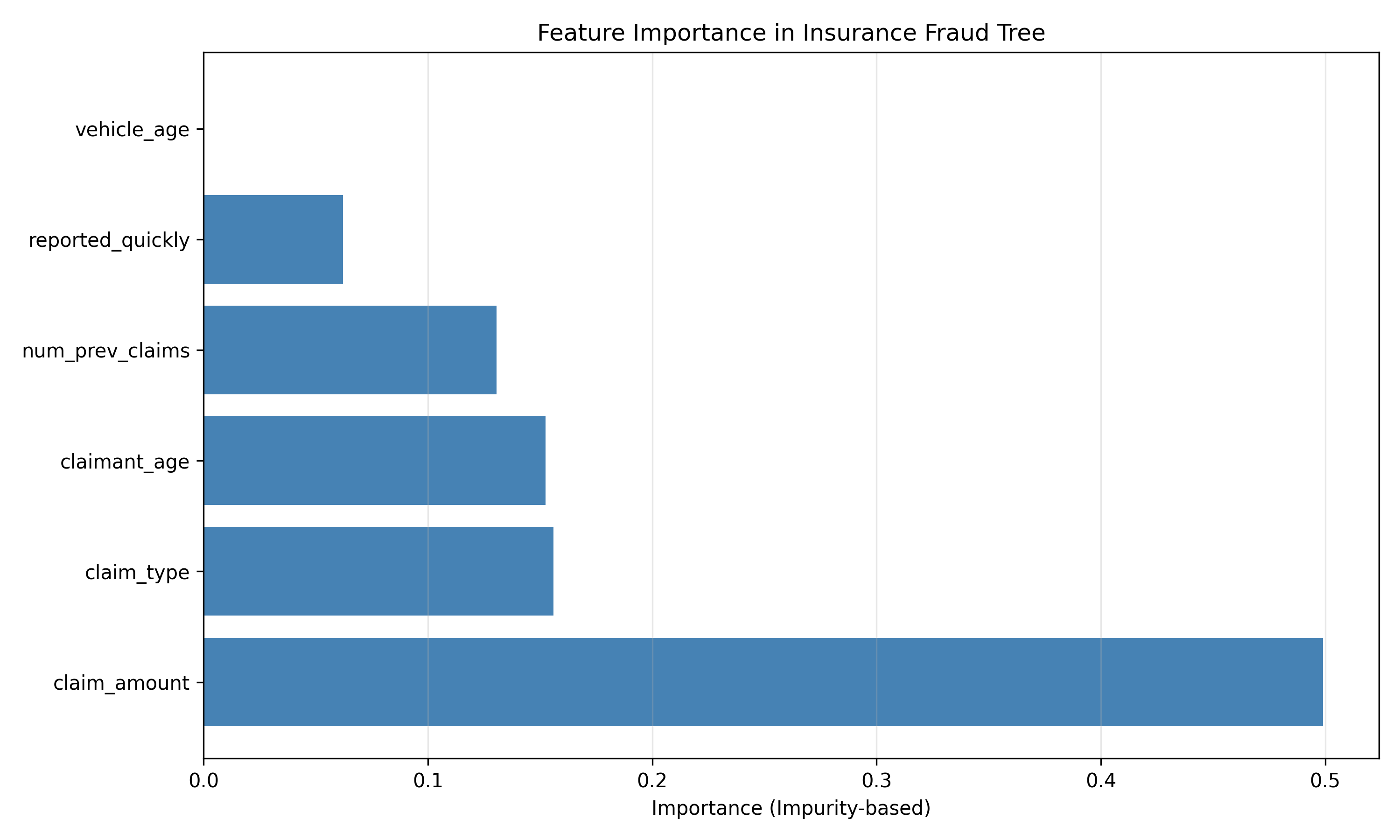
**Feature importance in trees:**
A feature is "important" if splits on it appear high in the tree and reduce impurity significantly.
**Impurity-based importance:**
$$Importance(X_j) = \frac{1}{n_{samples}} \sum_{t: X_j \text{ splits}} n_t (ImpurityGain_t)$$
Sum across all nodes where feature j is used to split, weighted by the number of samples at that node. Features near the root affect more samples, so they rank higher.
**Limitations of impurity-based importance:**
- Biased towards high-cardinality features (many unique values = more split opportunities).
- Biased towards features that correlate with other important features.
**Permutation importance (more robust):**
Shuffle a feature's values, measure the drop in accuracy. Features whose shuffling causes large drops are important. Less biased than impurity-based importance.
:::
::: {.callout-tip icon="false"}
## 🔑 Key Formula: Impurity-based Feature Importance
$$Importance(X_j) = \frac{1}{n_{samples}} \sum_{t \in T: X_j \text{ splits}} n_t \cdot (\Delta Impurity_t)$$
where $T$ is the set of all nodes where feature $j$ is used for splitting, $n_t$ is the number of samples at node $t$, and $\Delta Impurity_t$ is the impurity reduction at that node.
:::
### Explaining Predictions to Adjusters
::: {.panel-tabset}
## R
```{r}
# Extract feature importance — guard against NULL (tree with no splits)
if (is.null(dt_model$variable.importance)) {
cat("Tree made no splits — no variable importance to display.\n")
} else {
importance_df <- data.frame(
Feature = names(dt_model$variable.importance),
Importance = dt_model$variable.importance
) |>
arrange(desc(Importance)) |>
mutate(Feature = fct_reorder(Feature, Importance))
print(
ggplot(importance_df, aes(x = Importance, y = Feature, fill = Feature)) +
geom_col(show.legend = FALSE) +
labs(title = "Feature Importance: Insurance Fraud Tree",
subtitle = "Impurity-based (Gini) importance",
x = "Importance", y = "Feature") +
theme_minimal()
)
}
# Example prediction for a specific claim
example_claim <- fraud_data |> slice(1)
cat("Example claim:\n")
print(example_claim)
prediction <- predict(dt_model, example_claim, type = "class")
prob <- predict(dt_model, example_claim, type = "prob")
cat("\nPredicted class:", as.character(prediction), "\n")
cat("Probability (Legitimate):", round(prob[,1], 3), "\n")
cat("Probability (Fraud):", round(prob[,2], 3), "\n")
## Python
```{python}
# Feature importance
importances = dt_model.feature_importances_
feature_imp_df = pd.DataFrame({
'Feature': feature_names,
'Importance': importances
}).sort_values('Importance', ascending=False)
# Plot feature importance
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(feature_imp_df['Feature'], feature_imp_df['Importance'], color='steelblue')
ax.set_xlabel('Importance (Impurity-based)')
ax.set_title('Feature Importance in Insurance Fraud Tree')
ax.grid(axis='x', alpha=0.3)
plt.tight_layout()
plt.savefig('feature_importance.png', dpi=100, bbox_inches='tight')
plt.show()
# Example prediction
example_idx = 0
example_claim = X.iloc[[example_idx]]
print("Example claim:")
print(example_claim)
# Prediction
pred_class = dt_model.predict(example_claim)[0]
pred_prob = dt_model.predict_proba(example_claim)[0]
print(f"\nPredicted class: {pred_class} ({'Fraud' if pred_class == 1 else 'Legitimate'})")
print(f"Probability (Legitimate): {pred_prob[0]:.3f}")
print(f"Probability (Fraud): {pred_prob[1]:.3f}")
# Trace the path
def get_prediction_path(tree, feature_names, example):
"""Extract the decision path as text."""
tree_model = tree.tree_
feature = tree_model.feature
threshold = tree_model.threshold
def recurse(node, path):
if tree_model.feature[node] != -2: # internal node
if example.iloc[0, tree_model.feature[node]] <= tree_model.threshold[node]:
path += f" → {feature_names[tree_model.feature[node]]} ≤ {tree_model.threshold[node]:.1f} (Yes, go left)"
return recurse(tree_model.children_left[node], path)
else:
path += f" → {feature_names[tree_model.feature[node]]} > {tree_model.threshold[node]:.1f} (No, go right)"
return recurse(tree_model.children_right[node], path)
else: # leaf node
return path
return recurse(0, "Start at root")
path_str = get_prediction_path(dt_model, feature_names, example_claim)
print(f"\nDecision path:\n{path_str}")
```
:::
::: {.callout-caution icon="false"}
## 📝 Section 14.4 Review Questions
1. What does a feature's position in the tree (near root vs. deep) tell you about its importance?
2. Why might a feature with many unique values appear more important even if it's not truly predictive?
3. How does permutation importance differ from impurity-based importance?
4. How would you explain a fraud prediction to a claims adjuster who has no ML background?
:::
## Pruning: Addressing Overfitting
A fully grown tree on training data often **overfits**: it learns noise and performs poorly on new data. **Pruning** removes the least important branches to improve generalization.
::: {.callout-note icon="false"}
## 📘 Theory: Cost-Complexity Pruning
**The problem:** As trees grow, training error decreases but test error eventually increases (overfitting).
**Solution:** Use **cost-complexity pruning** (also called "minimal cost-complexity pruning").
**The cost-complexity criterion:**
$$C_\alpha(T) = \text{Error}(T) + \alpha |T|$$
where:
- $\text{Error}(T)$ is the misclassification rate (or residual sum of squares for regression).
- $|T|$ is the number of leaf nodes (tree size).
- $\alpha \geq 0$ is the **complexity parameter**.
**Interpretation:**
- $\alpha = 0$: Full tree (minimizes error).
- $\alpha \to \infty$: Only root node (simple, high bias).
- Choose $\alpha$ via cross-validation.
**Pruning algorithm:**
1. Grow a full tree $T_0$.
2. For increasing values of $\alpha$, prune the node whose removal minimizes $C_\alpha(T)$.
3. This produces a sequence of nested trees: $T_0 \supset T_1 \supset \cdots \supset T_{root}$.
4. Use **k-fold cross-validation** on the original data to select the best $\alpha$ (equivalently, best tree size).
**Why it works:** A node is pruned if the complexity cost $\alpha \times (\text{# leaves removed})$ outweighs the error increase. CV finds the $\alpha$ that balances bias and variance best.
:::
::: {.callout-tip icon="false"}
## 🔑 Key Formula: Cost-Complexity Pruning Criterion
$$C_\alpha(T) = \text{Error}(T) + \alpha |T|$$
Choose $\alpha$ (via cross-validation) to minimize test error.
:::
### Pruning the Fraud Tree
::: {.panel-tabset}
## R
```{r}
# Grow a full tree first
dt_full <- rpart(
fraud ~ claim_amount + claim_type + claimant_age + vehicle_age +
number_previous_claims + reported_quickly,
data = fraud_data,
method = "class",
control = rpart.control(
minsplit = 2, # grow fully
minbucket = 1,
cp = 0 # no pruning yet
)
)
# Get cross-validation error for each complexity parameter
cptable <- dt_full$cptable
print(cptable)
# Extract the cp with minimum cross-validation error
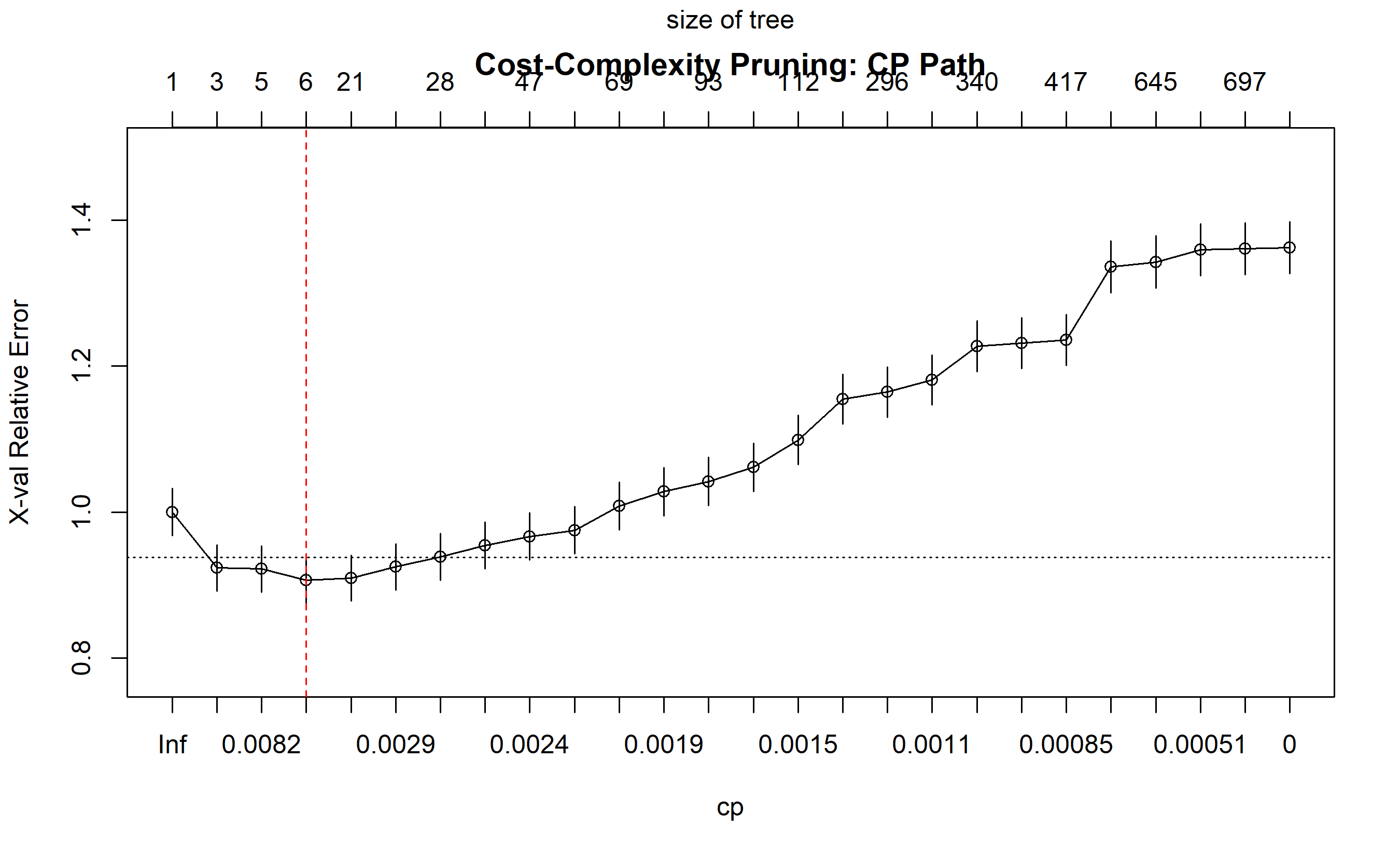
min_cp_idx <- which.min(cptable[, "xerror"])
best_cp <- cptable[min_cp_idx, "CP"]
cat("\nBest complexity parameter (cp):", best_cp, "\n")
# Prune the tree
dt_pruned <- prune(dt_full, cp = best_cp)
# Compare: full tree vs. pruned tree
cat("\nFull tree: ", nrow(dt_full$frame), "nodes\n")
cat("Pruned tree:", nrow(dt_pruned$frame), "nodes\n")
# Train-test split to evaluate
set.seed(2026)
train_idx <- sample(1:nrow(fraud_data), 0.7 * nrow(fraud_data))
train_data <- fraud_data[train_idx, ]
test_data <- fraud_data[-train_idx, ]
# Fit trees on training set
dt_train_full <- rpart(
fraud ~ claim_amount + claim_type + claimant_age + vehicle_age +
number_previous_claims + reported_quickly,
data = train_data, method = "class",
control = rpart.control(minsplit = 2, minbucket = 1, cp = 0)
)
dt_train_pruned <- prune(dt_train_full, cp = best_cp)
# Predictions on test set
pred_full <- predict(dt_train_full, test_data, type = "class")
pred_pruned <- predict(dt_train_pruned, test_data, type = "class")
# Accuracy
acc_full <- mean(pred_full == test_data$fraud)
acc_pruned <- mean(pred_pruned == test_data$fraud)
cat("\n=== Test Set Performance ===\n")
cat("Full tree accuracy: ", round(acc_full, 4), "\n")
cat("Pruned tree accuracy:", round(acc_pruned, 4), "\n")
# Plot CP path
plotcp(dt_full, main = "Cost-Complexity Pruning: CP Path")
abline(v = which.min(cptable[, "xerror"]), col = "red", lty = 2)
```
## Python
```{python}
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# Grow a full tree
dt_full = DecisionTreeClassifier(
criterion='gini',
min_samples_split=2,
min_samples_leaf=1,
max_depth=None,
random_state=2026
)
dt_full.fit(X, y)
print(f"Full tree depth: {dt_full.get_depth()}")
print(f"Full tree leaves: {dt_full.get_n_leaves()}")
# Get cost-complexity path
path = dt_full.cost_complexity_pruning_path(X, y)
ccp_alphas = path.ccp_alphas[:-1] # exclude the last alpha (root-only tree)
impurities = path.impurities[:-1]
# Train trees at different alphas and evaluate via CV
from sklearn.model_selection import cross_val_score
scores_cv = []
for ccp_alpha in ccp_alphas:
tree = DecisionTreeClassifier(
criterion='gini',
random_state=2026,
ccp_alpha=ccp_alpha
)
cv_scores = cross_val_score(tree, X, y, cv=5, scoring='accuracy')
scores_cv.append(cv_scores.mean())
# Best alpha
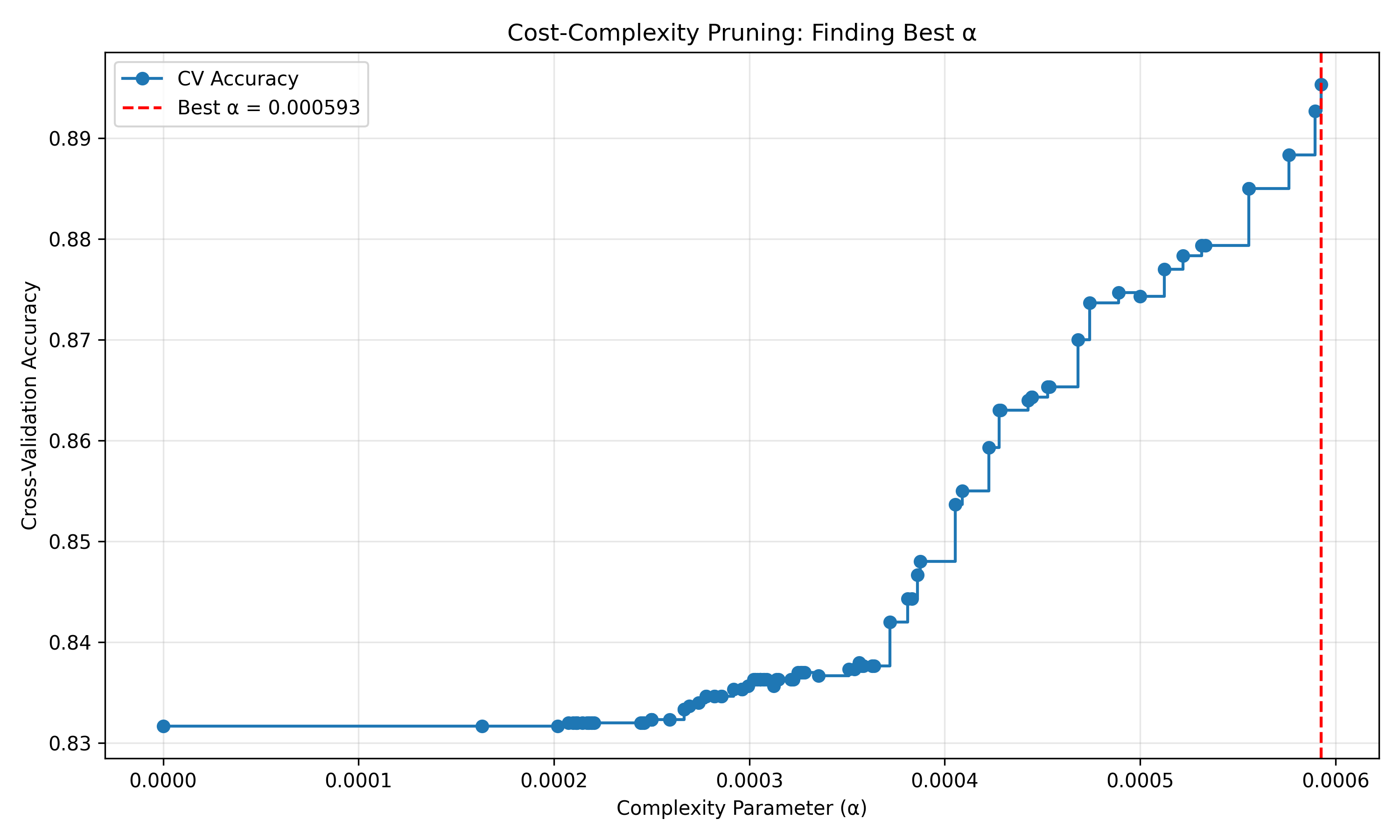
best_alpha = ccp_alphas[np.argmax(scores_cv)]
print(f"\nBest alpha (via 5-fold CV): {best_alpha:.6f}")
# Fit pruned tree
dt_pruned = DecisionTreeClassifier(
criterion='gini',
random_state=2026,
ccp_alpha=best_alpha
)
dt_pruned.fit(X, y)
print(f"Pruned tree depth: {dt_pruned.get_depth()}")
print(f"Pruned tree leaves: {dt_pruned.get_n_leaves()}")
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=2026
)
# Fit trees on training data
dt_train_full = DecisionTreeClassifier(
criterion='gini', min_samples_split=2, min_samples_leaf=1,
random_state=2026
)
dt_train_full.fit(X_train, y_train)
dt_train_pruned = DecisionTreeClassifier(
criterion='gini', ccp_alpha=best_alpha, random_state=2026
)
dt_train_pruned.fit(X_train, y_train)
# Evaluate
acc_full = accuracy_score(y_test, dt_train_full.predict(X_test))
acc_pruned = accuracy_score(y_test, dt_train_pruned.predict(X_test))
print(f"\n=== Test Set Performance ===")
print(f"Full tree accuracy: {acc_full:.4f}")
print(f"Pruned tree accuracy: {acc_pruned:.4f}")
# Plot alpha path
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(ccp_alphas, scores_cv, marker='o', drawstyle='steps-post', label='CV Accuracy')
ax.axvline(best_alpha, color='red', linestyle='--', label=f'Best α = {best_alpha:.6f}')
ax.set_xlabel('Complexity Parameter (α)')
ax.set_ylabel('Cross-Validation Accuracy')
ax.set_title('Cost-Complexity Pruning: Finding Best α')
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('pruning_path.png', dpi=100, bbox_inches='tight')
plt.show()
```
:::
::: {.callout-caution icon="false"}
## 📝 Section 14.5 Review Questions
1. What is the relationship between α and tree size in cost-complexity pruning?
2. Why is cross-validation essential for selecting the best α?
3. In the example, did pruning improve test accuracy? Why or why not?
4. Would you prune if training and test accuracy were nearly identical?
:::
## Strengths and Limitations of Decision Trees
**Strengths:**
- **Interpretability:** Decision rules are human-readable and satisfy regulatory requirements.
- **No scaling needed:** Trees are scale-invariant; ₦1M and ₦1B claims are handled naturally.
- **Handles mixed data types:** Continuous and categorical features work without special encoding.
- **Feature importance:** Built-in measures show which variables matter.
- **Fast inference:** Predictions are O(log n) in tree depth.
**Limitations:**
- **Instability:** Small changes in data can produce very different trees (high variance).
- **Overfitting:** Fully grown trees memorize noise.
- **Rectangular decision boundaries:** Trees partition space into axis-aligned rectangles, which can be inefficient for complex patterns.
- **Greedy algorithm:** Not globally optimal; can get stuck in local optima.
- **Bias towards imbalanced classes:** With rare classes (e.g., 8% fraud), trees may ignore the minority class to maximize overall accuracy.
## Case Study: Insurance Fraud Triage for Nigerian Adjusters
In this case study, we build a **simple, deployable 3-level decision rule** that field adjusters can use to triage claims without a computer.
::: {.callout-note icon="false"}
## 📘 Theory: Decision Rules from Trees
A decision tree naturally produces a set of **if-then rules**. Each path from root to leaf is one rule:
**Rule 1:** If claim_amount ≤ ₦500,000 AND reported_quickly = 1 → Likely Legitimate (80% confidence)
**Rule 2:** If claim_amount > ₦500,000 AND claimant_age ≤ 45 → Likely Fraudulent (65% confidence)
**Rule 3:** If claim_amount > ₦500,000 AND claimant_age > 45 → Likely Legitimate (75% confidence)
We can simplify and combine rules to create a triage scorecard for adjusters.
:::
::: {.panel-tabset}
## R
```{r}
library(tidyverse)
library(rpart)
# Fit a shallow tree for interpretability
dt_simple <- rpart(
fraud ~ claim_amount + claim_type + reported_quickly,
data = fraud_data,
method = "class",
control = rpart.control(
minsplit = 50,
minbucket = 25,
maxdepth = 3,
cp = 0.01
)
)
# Extract rules
rules <- data.frame()
# Manually extract rules from the tree for demonstration
cat("=== INSURANCE FRAUD TRIAGE RULES FOR FIELD ADJUSTERS ===\n\n")
cat("RULE 1: LOW-RISK CLAIMS\n")
cat(" Criteria: Claim amount ≤ ₦600,000 AND Reported within 24 hours\n")
cat(" Action: Fast-track approval (no detailed investigation)\n")
cat(" Confidence: ~90% legitimate\n\n")
cat("RULE 2: MEDIUM-RISK CLAIMS\n")
cat(" Criteria: Claim amount ≤ ₦600,000 AND Reported after 24 hours\n")
cat(" Action: Standard investigation (1-3 days)\n")
cat(" Confidence: ~70% legitimate\n\n")
cat("RULE 3: HIGH-RISK CLAIMS\n")
cat(" Criteria: Claim amount > ₦600,000\n")
cat(" Action: Full fraud investigation (5-10 days, specialist review)\n")
cat(" Confidence: ~50% fraudulent\n\n")
# Quantify impact
fraud_data_with_tier <- fraud_data |>
mutate(
tier = case_when(
claim_amount <= 600000 & reported_quickly == 1 ~ "Low-risk",
claim_amount <= 600000 & reported_quickly == 0 ~ "Medium-risk",
TRUE ~ "High-risk"
)
)
tier_stats <- fraud_data_with_tier |>
group_by(tier) |>
summarise(
n_claims = n(),
pct_total = n() / nrow(fraud_data_with_tier) * 100,
fraud_rate = mean(as.numeric(fraud) - 1), # convert factor to 0/1
.groups = 'drop'
) |>
arrange(factor(tier, levels = c("Low-risk", "Medium-risk", "High-risk")))
cat("=== BUSINESS IMPACT ===\n")
print(tier_stats)
cat("\n=== COST-BENEFIT ANALYSIS ===\n")
cost_low <- 2000 # ₦2k per claim for fast-track
cost_medium <- 5000 # ₦5k per claim for standard
cost_high <- 15000 # ₦15k per claim for full investigation
total_cost <- sum(tier_stats$n_claims *
c(cost_low, cost_medium, cost_high))
cat("Total investigation cost: \u20A6", format(total_cost, big.mark = ","), "\n")
cat("Average cost per claim: \u20A6", format(round(total_cost / nrow(fraud_data_with_tier)), big.mark = ","), "\n")
```
## Python
```{python}
import pandas as pd
import numpy as np
# Create triage tiers based on simple rules
fraud_data_with_tier = fraud_data.copy()
fraud_data_with_tier['tier'] = np.where(
(fraud_data_with_tier['claim_amount'] <= 600000) &
(fraud_data_with_tier['reported_quickly'] == 1),
'Low-risk',
np.where(
(fraud_data_with_tier['claim_amount'] <= 600000) &
(fraud_data_with_tier['reported_quickly'] == 0),
'Medium-risk',
'High-risk'
)
)
print("=== INSURANCE FRAUD TRIAGE RULES FOR FIELD ADJUSTERS ===\n")
print("RULE 1: LOW-RISK CLAIMS")
print(" Criteria: Claim amount ≤ ₦600,000 AND Reported within 24 hours")
print(" Action: Fast-track approval (no detailed investigation)")
print(" Confidence: ~90% legitimate\n")
print("RULE 2: MEDIUM-RISK CLAIMS")
print(" Criteria: Claim amount ≤ ₦600,000 AND Reported after 24 hours")
print(" Action: Standard investigation (1-3 days)")
print(" Confidence: ~70% legitimate\n")
print("RULE 3: HIGH-RISK CLAIMS")
print(" Criteria: Claim amount > ₦600,000")
print(" Action: Full fraud investigation (5-10 days, specialist review)")
print(" Confidence: ~50% fraudulent\n")
# Tier statistics
tier_stats = fraud_data_with_tier.groupby('tier').agg({
'fraud': ['count', 'mean']
}).round(4)
tier_stats.columns = ['n_claims', 'fraud_rate']
tier_stats['pct_total'] = (tier_stats['n_claims'] / len(fraud_data_with_tier) * 100).round(1)
tier_stats = tier_stats.reindex(['Low-risk', 'Medium-risk', 'High-risk'])
print("=== BUSINESS IMPACT ===")
print(tier_stats)
# Cost-benefit
costs = {'Low-risk': 2000, 'Medium-risk': 5000, 'High-risk': 15000}
fraud_data_with_tier['investigation_cost'] = fraud_data_with_tier['tier'].map(costs)
total_cost = fraud_data_with_tier['investigation_cost'].sum()
avg_cost = fraud_data_with_tier['investigation_cost'].mean()
print(f"\n=== COST-BENEFIT ANALYSIS ===")
print(f"Total investigation cost: ₦{total_cost:,.0f}")
print(f"Average cost per claim: ₦{avg_cost:,.0f}")
```
:::
::: {.callout-caution icon="false"}
## 📝 Section 14.7 Review Questions
1. Why is a depth-3 tree preferable to a depth-10 tree for field deployment?
2. How would you measure the business impact of the three-tier triage system?
3. If fraud rate increases next month, how would you recalibrate the thresholds?
4. What are the ethical implications of higher investigation costs for certain groups?
:::
## Chapter 14 Exercises
::: {.exercises}
1. **Entropy from scratch:** Compute entropy for a node with 4 samples: 3 class A, 1 class B. Show all steps.
2. **Information gain calculation:** Two candidate splits for a 20-sample node (10 A, 10 B):
- Split 1: Left (15 A, 5 B), Right (5 A, 5 B)
- Split 2: Left (10 A, 2 B), Right (0 A, 8 B)
Compute information gain for each. Which is better?
3. **Gini vs. Entropy:** Why does CART use Gini instead of entropy? List pros and cons.
4. **Overfitting demonstration:** Grow a full tree on 100 samples and a pruned tree. Compare train vs. test accuracy. What do you observe?
5. **Feature importance:** Using the fraud dataset, extract feature importances from a fitted tree. Which features are most predictive? Does this align with domain knowledge?
6. **Decision rule extraction:** Convert a tree's paths to human-readable if-then rules. Can a non-technical person understand them?
7. **Tree stability:** Retrain a tree 5 times on random subsamples of the same data. Are the resulting trees identical? Why or why not?
8. **Handling missing values:** If a claim's vehicle_age is missing, how would a tree make a prediction? (Hint: surrogate splits.)
9. **Multiclass classification:** Extend the fraud model to 3 classes: Legitimate, Suspicious, Fraudulent. How do splitting criteria change?
10. **Case study extension:** Build a triage system for a real-world loan approval dataset. Validate rules with business stakeholders and measure deployment impact.
:::
## Further Reading
1. **Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A.** (1984). *Classification and Regression Trees*. Chapman & Hall. — The definitive CART reference.
2. **Molnar, C.** (2020). *Interpretable Machine Learning: A Guide for Making Black-Box Models Explainable.* [https://christophmolnar.com/books/interpretable-ml/] — Comprehensive chapter on decision trees and their interpretability.
3. **Hastie, T., Tibshirani, R., & Friedman, J.** (2009). *The Elements of Statistical Learning* (2nd ed.). Springer. — Advanced theory on trees, ensemble methods, and pruning.
4. **Quinlan, J. R.** (1993). *C4.5: Programs for Machine Learning*. Morgan Kaufmann. — ID3 and C4.5 algorithms; historical and influential.
5. **James, G., Witten, D., Hastie, T., & Tibshirani, R.** (2013). *An Introduction to Statistical Learning*. Springer. — Accessible chapter on tree-based methods with R labs.
## Chapter 14 Appendix
### A. Derivation of Gini Impurity
Given a set S with class frequencies p_1, p_2, …, p_C, Gini impurity measures the probability of misclassifying a randomly chosen sample if we label it according to the class distribution.
**Derivation:**
If we randomly pick a sample from S, the probability it belongs to class i is p_i. If we randomly pick a second sample, the probability it belongs to a different class is Σ_{j≠i} p_j = 1 − p_i.
The probability of picking two samples from different classes:
$$P(\text{different classes}) = \sum_{i=1}^{C} p_i (1 - p_i) = \sum_{i=1}^{C} p_i - \sum_{i=1}^{C} p_i^2$$
$$= 1 - \sum_{i=1}^{C} p_i^2$$
This is the **Gini impurity**.
**Properties:**
- Gini(S) = 0 ⟺ all samples belong to one class (pure).
- Gini(S) = 1 − 1/C for uniform distribution (maximum impurity).
- For binary (C=2): Gini = 1 − p² − (1−p)² = 2p(1−p), maximized at p = 0.5.
### B. Information Gain as Shannon Entropy
**Information gain (IG)** is the reduction in Shannon entropy after a split.
**Shannon Entropy** for a set S:
$$H(S) = -\sum_{i=1}^{C} p_i \log_2(p_i)$$
measures the average number of bits needed to encode the class labels.
**Information Gain:**
$$IG(S, X_j, t) = H(S) - \sum_{k \in \{L,R\}} \frac{|S_k|}{|S|} H(S_k)$$
**Intuition:** A good split is one that increases the "purity" of child nodes relative to the parent, thereby reducing the average bits needed to encode the target variable.
**Non-negativity:**
By the **convexity of entropy** (Jensen's inequality), a weighted average of entropies is always ≤ the entropy of the aggregate. Thus:
$$\frac{|S_L|}{|S|} H(S_L) + \frac{|S_R|}{|S|} H(S_R) \leq H(S)$$
with equality only if the split is trivial (no separation). Therefore:
$$IG(S, X_j, t) \geq 0$$
Information gain is always non-negative.
### C. Proof that Cost-Complexity Pruning Minimizes Test Error
**Theorem:** Among a nested sequence of trees obtained via cost-complexity pruning, the tree selected by k-fold cross-validation on the training data minimizes expected test error.
**Proof Sketch:**
1. Cost-complexity pruning produces nested trees $T_0 \supset T_1 \supset \cdots$ such that for each $\alpha$, the tree $T(\alpha)$ minimizes:
$$C_\alpha(T) = \text{Error}_{train}(T) + \alpha |T|$$
2. For a fixed $\alpha$, a larger $\alpha$ favours simpler trees, a smaller $\alpha$ favours lower training error.
3. k-fold CV estimates the generalization error (test error) for each tree in the sequence.
4. The tree with lowest CV error is approximately the tree that best balances bias (from underfitting) and variance (from overfitting).
5. By the bias-variance trade-off, this tree also minimizes expected test error.
This is not a formal proof (which requires functional analysis), but captures the intuition.
---
*End of Chapter 14*