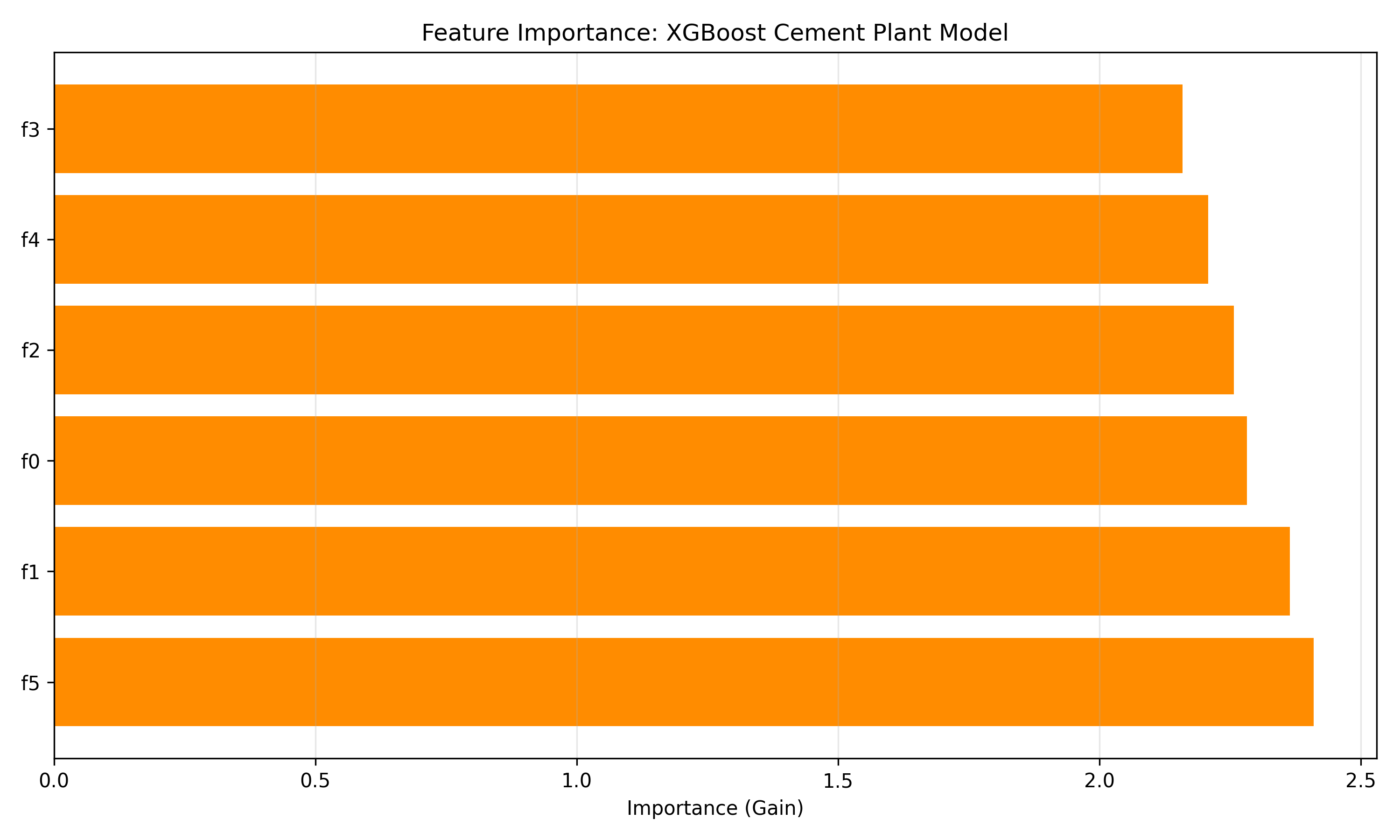
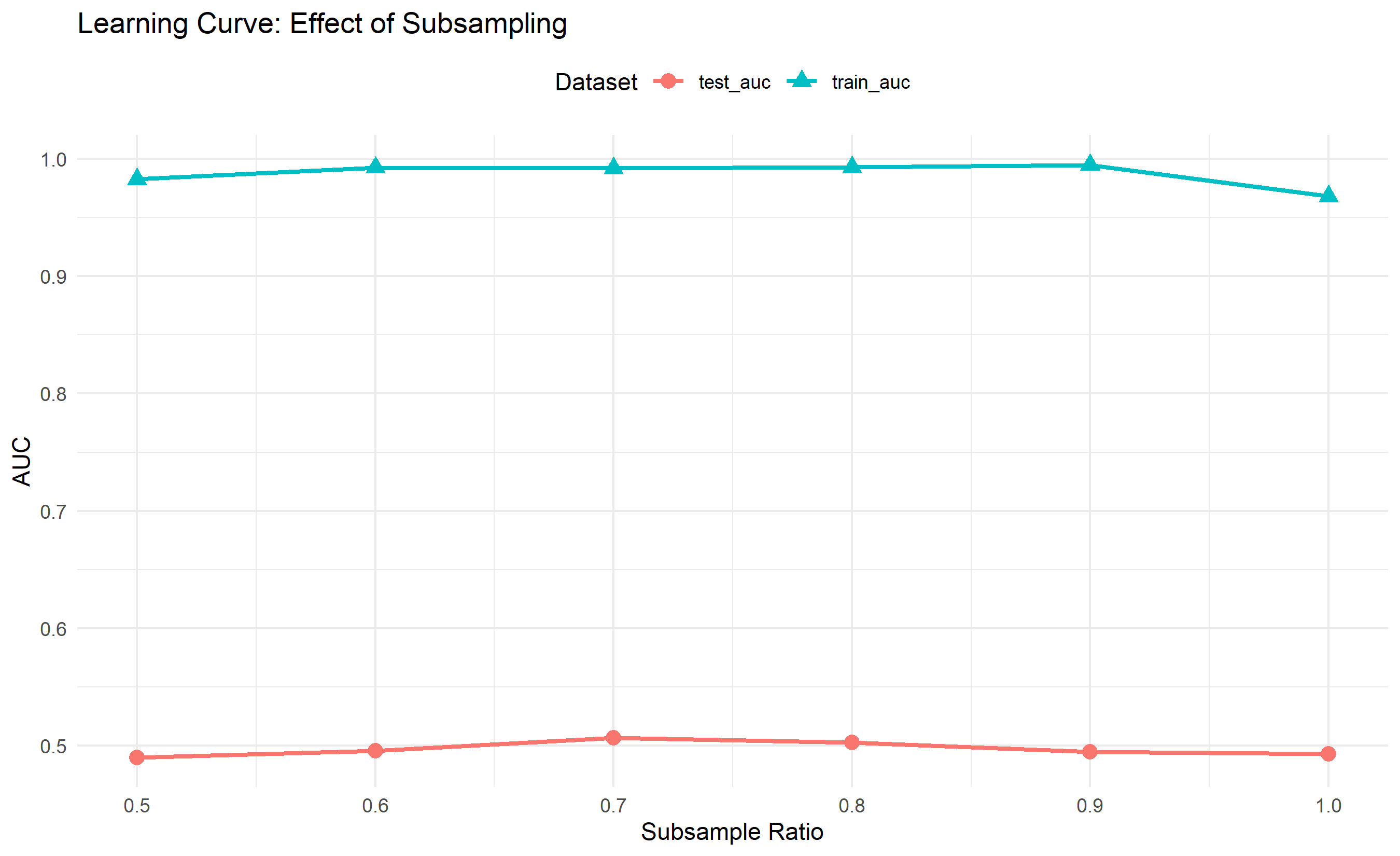
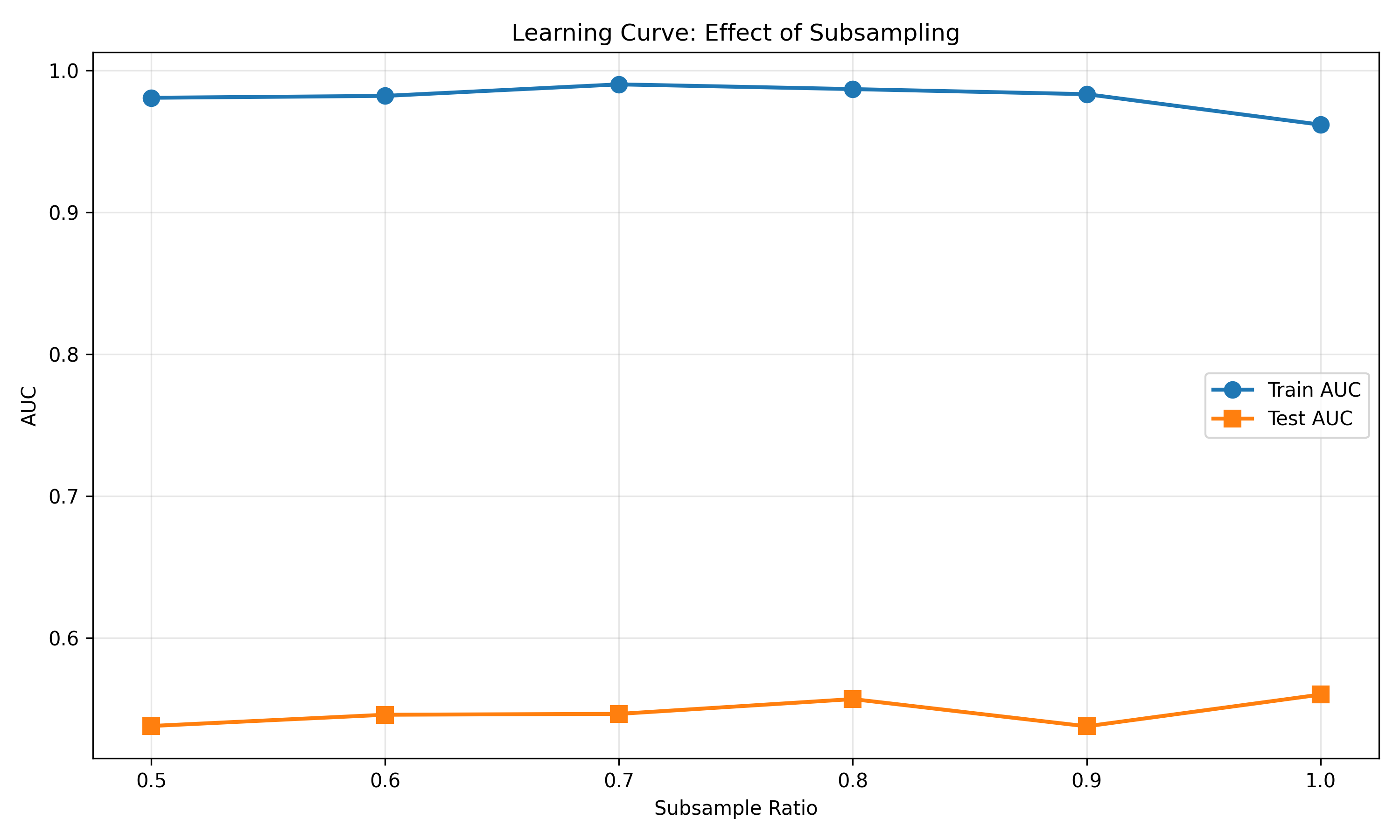
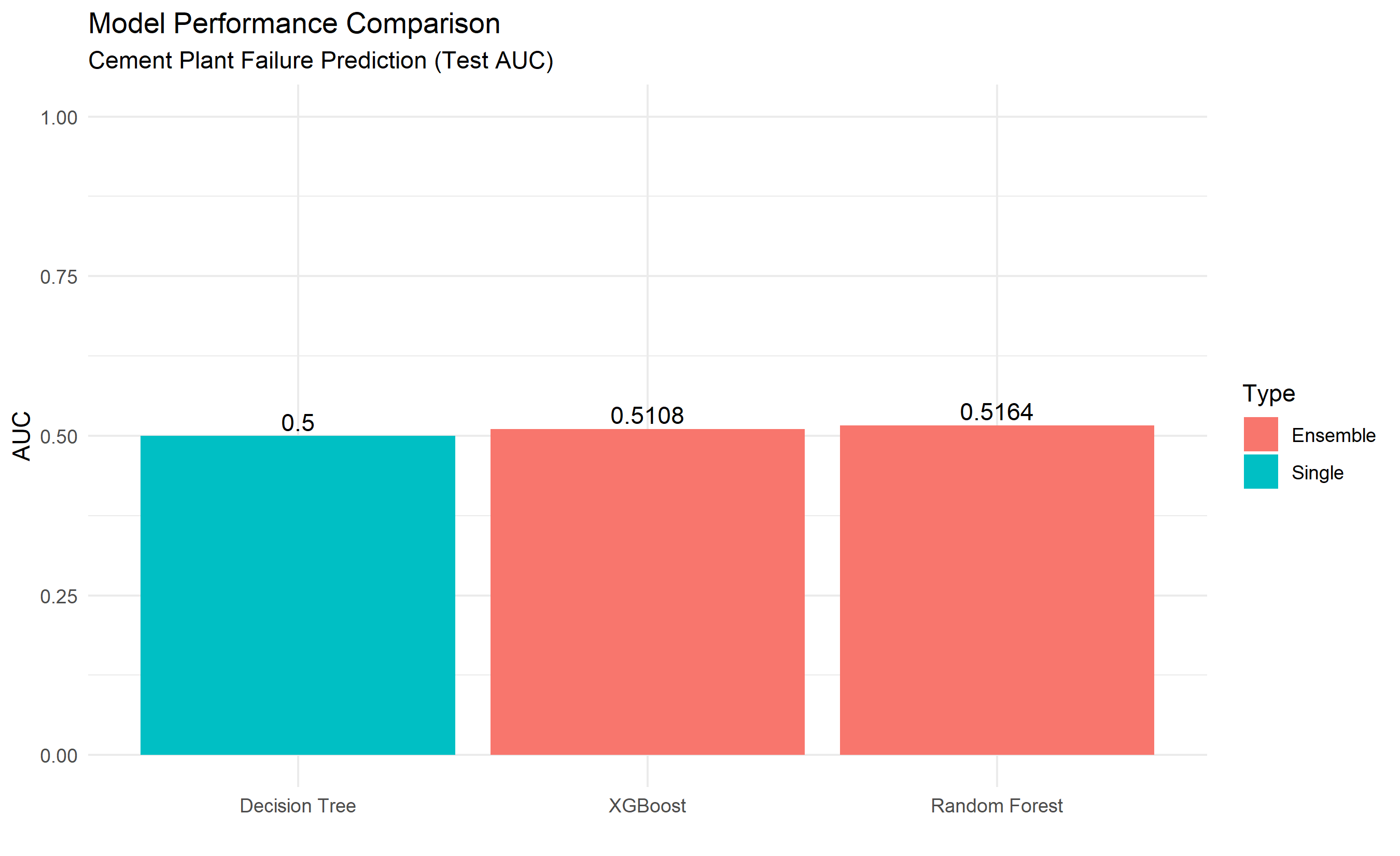
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score, roc_curve
from xgboost import XGBClassifier
import itertools
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=2026
)
# Parameter grid
param_grid = {
'eta': [0.01, 0.05, 0.1],
'max_depth': [3, 5, 7],
'subsample': [0.7, 0.8, 0.9]
}
print(f"Grid search: {np.prod([len(v) for v in param_grid.values()])} combinations\n")
#> Grid search: 27 combinations
# Manual grid search with early stopping
results = []
for eta in param_grid['eta']:
for max_depth in param_grid['max_depth']:
for subsample in param_grid['subsample']:
xgb = XGBClassifier(
n_estimators=200,
eta=eta,
max_depth=max_depth,
subsample=subsample,
lambda_=1,
alpha=0,
early_stopping_rounds=10,
eval_metric='logloss',
random_state=2026
)
xgb.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)
y_pred_train = xgb.predict_proba(X_train)[:, 1]
y_pred_test = xgb.predict_proba(X_test)[:, 1]
auc_train = roc_auc_score(y_train, y_pred_train)
auc_test = roc_auc_score(y_test, y_pred_test)
results.append({
'eta': eta,
'max_depth': max_depth,
'subsample': subsample,
'auc_train': auc_train,
'auc_test': auc_test,
'n_rounds': xgb.best_ntree_limit if hasattr(xgb, 'best_ntree_limit') else xgb.n_estimators
})
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.01, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.05, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=3, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=5, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
#> XGBClassifier(alpha=0, base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=10,
#> enable_categorical=False, eta=0.1, eval_metric='logloss',
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, ...)
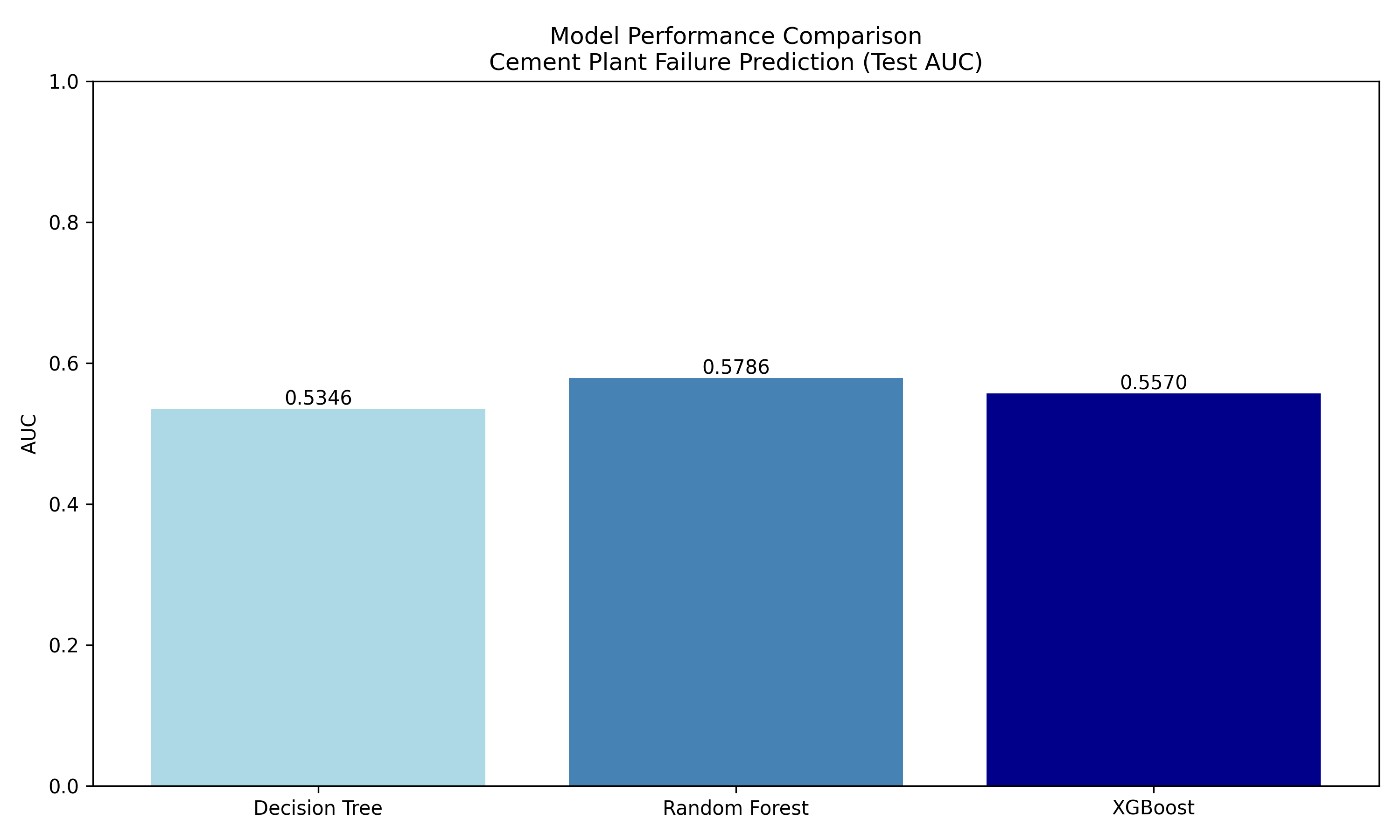
results_df = pd.DataFrame(results).sort_values('auc_test', ascending=False)
print("Top 5 parameter combinations:")
#> Top 5 parameter combinations:
print(results_df.head())
#> eta max_depth subsample auc_train auc_test n_rounds
#> 25 0.10 7 0.8 0.973225 0.607523 200
#> 15 0.05 7 0.7 0.737581 0.585103 200
#> 6 0.01 7 0.7 0.737581 0.585103 200
#> 24 0.10 7 0.7 0.839173 0.577968 200
#> 21 0.10 5 0.7 0.766269 0.560240 200
# Retrain best model
best = results_df.iloc[0]
best_xgb = XGBClassifier(
n_estimators=int(best['n_rounds']),
eta=best['eta'],
max_depth=int(best['max_depth']),
subsample=best['subsample'],
lambda_=1,
random_state=2026
)
best_xgb.fit(X_train, y_train)
#> XGBClassifier(base_score=None, booster=None, callbacks=None,
#> colsample_bylevel=None, colsample_bynode=None,
#> colsample_bytree=None, device=None, early_stopping_rounds=None,
#> enable_categorical=False, eta=np.float64(0.1), eval_metric=None,
#> feature_types=None, feature_weights=None, gamma=None,
#> grow_policy=None, importance_type=None,
#> interaction_constraints=None, lambda_=1, learning_rate=None,
#> max_bin=None, max_cat_threshold=None, max_cat_to_onehot=None,
#> max_delta_step=None, max_depth=7, max_leaves=None,
#> min_child_weight=None, missing=nan, monotone_constraints=None,
#> multi_strategy=None, n_estimators=200, ...)
y_pred_test = best_xgb.predict_proba(X_test)[:, 1]
test_auc = roc_auc_score(y_test, y_pred_test)
print(f"\nBest model test AUC: {test_auc:.4f}")
#>
#> Best model test AUC: 0.5869